
1 접근전략
1-1 Background

객체가 있을법한 위치를 특정짓고 객체가 어떤 객체인지를 예측하는 두가지 단계를 진행하는 2Stage Detectors를 배워보자
2 R-CNN
2-1 Overview

후보영역을 추출하는 방법
1) sliding window
- sliding window방식은 무수히 많은 영역이 추출되고 거의 다 배경으로써 의미가 없는 영역이기때문에 RCNN에서는 사용되지 않음

2) selective Search
- 이미지에 존재하는 특성(shape)들을 추출해서 영역을 만들고 무수히 많이 만들어진 영역들을 통합하면서 줄여나간다

2-2 Pipeline
1) 입력이미지 받기
2) Selective Search를 통해 2000개의 ROI(Regions of Interest)를 추출
3) ROI의 크기를 조절해 동일한 사이즈로 변형
- CNN의 마지막인 FC layer의 입력사이즈가 고정이므로 이 과정을 수행
4) ROI를 CNN에 넣어 feature를 추출
- 각 region마다 4096 dim feature vector 추출
- pretrained Alexnet 구조 활용
5-1) CNN을 통해 나온 feature를 SVM에 넣어 분류 진행
- Input: 2000 x 4096 features
- Output: class(c+1) + confidence scores -> 클래스수 + 1은 배경여부임
5-2) CNN을 통해 나온 feature를 regression을 통해 bounding box 예측
- 중심점의 좌표와, 가로, 세로를 모델에 넣어준다.
- 예측한 중심점의 좌표를 Ground truth box의 중심점으로 옮기는 학습에 필요한 delta와 width, height를 ground truth box의 width와 height로 옮기는 delta를 학습해야한다

2-3 Training
1) AlexNet
1-1 Domain specific finetuning
1-2 Dataset 구성
- IOU > 0.5: positive samples
- IOU < 0.5: negative samples
- positive samples 32, negative samples 96로 구성
2) Linear SVM
2-1 Dataset 구성
- Ground truth: positive samples
- IOU < 0.3: negative samples
- Positive samples 32, negative samples 96
2-2 Hard negative mining
- 배경으로 식별하기 어려운 샘플들을 강제로 다음 배치의 negative sample로 mining하는 방법
3) Bbox Regressor
3-1 Dataset구성
- IOU > 0.06: positive samples
3-2 Loss function
- MSE loss
-> width, heigth, 중심점을 얼마나 이동시킬지 delta에 대한 학습방법
2-4 Shortcomings
1) 2000개의 Region을 각각 CNN 통과
2) 강제 Warping, 성능 하락 가능성
3) CNN, SVM classifier, bounding box regressor, 따로 학습
4) End-to-End X
3 SPPNet
3-1 Overview
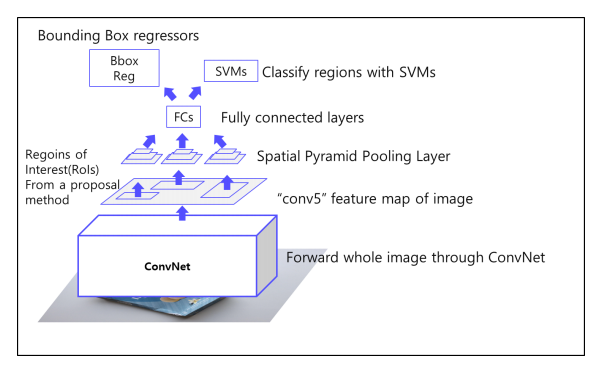
R-CNN의 한계점
- Convolution Network의 입력 이미지가 고정되어있음
이미지를 고정된 크기로 자르거나(crop) 비율을 조정(wrap)해야함
- ROI(Region of Interest)마다 CNN통과
하나의 이미지에 대해서 2000번 CNNN을 통과해야 하기 때문에 시간이 오래걸림
3-2 Spatial Pyramid Pooling

하나의 이미지에서 여러개 feature를 뽑음
위의 과정은 wraping의 효과를 볼 수 있다
3-3 Shortcomings
먼저 CNN을 통과해서 ROI를 추출하였고,
wraping을 하지않고 spp를 사용하여 고정된 효과를 얻음
기존의 RCNN의 문제에서 두개를 해결
1) 2000개의 RoI 각각 CNN 통과
2) 강제 Warping, 성능 손실 가능성
3) CNN, SVM classifier, bounding box regression, 따로 학습
4) End-to-End X
4 Fast R-CNN

4-1 Pipeline
1) VGG16사용
2) ROI projection을 통해 feature map상에서 ROI를 계산
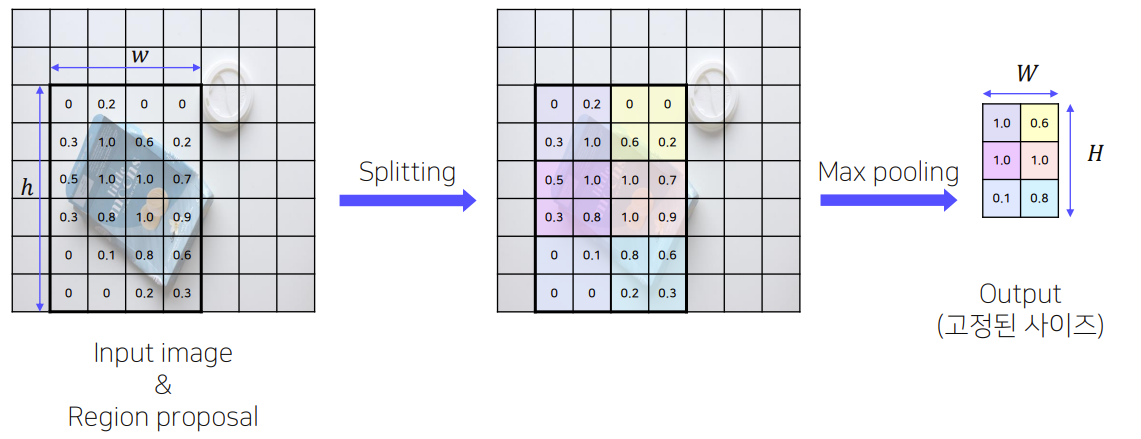
3) ROI pooling을 통해 일정한 크기의 feature가 추출
- 고정된 vector를 얻기 위한 과정
- SPP 사용(pyramid level:1 , target grid size: 7x7)
4) Fully connected layer 이후, Softmax Classifier와 Bounding Box Regressor
- 클래스개수: C+1 (배경1)
4-2 Training
1) multi task loss 사용
- classification loss + bounding box regression
2) loss function
- classification: cross entropy
- BB regressor: Smooth L1 ( 아웃라이어에 덜 민감하기 때문에 사용 )

3) dataset 구성
- IoU> 0.5 : positive samples
- 0.1< IoU<0.5: negative samples
- positive samples 25%, negative samples 75%
4) Hierarchical sampling
- R-CNN의 경우 이미지에 존재하는 RoI를 전부 저장해 사용
- 한 배치에 서로 다른 이미지의 RoI가 포함됨
- Fast R-CNN의 경우 한 배치에 한 이미지의 RoI만을 포함
- 한 배치안에서 연산과 메모리를 공유할 수 있음
4-3 Shortcomings
selective search는 cpu에서 돌아가는 알고리즘이기 때문에 완전한 end to end라고하기는 어렵다
1) 2000개의 RoI 각각 CNN 통과
2) 강제 Warping, 성능 손실 가능성
3) CNN, SVM classifier, bounding box regression, 따로 학습
4) End-to-End X
5. Faster R-CNN

5-1 Pipeline
1) 이미지를 CNN에 넣어 feature maps 추출 (CNN을 한번만 사용)
2) RPN(Region proposal network)을 통해 ROI 계산
- 기존의 selective search 대체
- Anchor box 개념 사용
Anchor box
이미지가 conv를 통과해서 featuremap이 나오게 되고 각 피쳐맵의 각 셀마다 다양한 스케일과 비율을 가진 k개의 anchor box가 나오게된다
ex) featuremap이 64x64고 9개의 anchor박스를 사용하게된다면 64*64*9 = 약 36000 개의 roi를 사용하게된다
이 anchorbox가 객체를 포함하고 있는지 없는지를 찾아내야하고 좌표를 미세조정 할 필요가있다.
이런일을 하는게 RPN이다
RPN

k개의 anchorbox가 있을때 각 anchor box가 객체를 포함하고 있는지 아닌지를 score로 예측하는 classification head가 있고
위치를 미세조정하는 coordinates head가 존재한다
ex)
1) backbone CNN을 통과하여 나온 featuremap을 input으로 받은 (H,W,C)
2-1) 3x3 conv수행하여 intermediate layer 생성 -> 채널개수를 맞춰줌
2-2) 1x1 conv를 수행하여 binary classification 수행하여 18개의 채널로 변환
-> 2(객체가 있는지 없는지) x 9(num of anchors)개의 채널
2-3) 1x1 conv 수행하여 bounding box regression 수행
-> 4(width,height, 중심좌표) x 9(ancorbox의 수)개의 채널생성

요약
- 각 anchor box에 대해서 score가 나오게된다.
- 스코어가 높으면 이 box는 객체를 포함하고 있을 확률이 높다는 것을 의미
- 스코어 기준으로 정렬해서 Top N개의 ancor box를 select한다
- select된 box를 어떻게 조절할지를 coordinates를 적용하여 width height 중심점이 변형되어 나오게됨

NMS
- RPN의 과정
- 유사한 RPN Proposals를 제거하기 위해 사용
- classs score를 기준으로 proposals 분류
- IoU가 0.7이상인 proposals 영역들은 중복된 영역으로 판단한 뒤 제거
- N개의 RoI를통해서 1000~2000개의 RoI가 나오게끔 NMS를 수행
ex)
- threshold를 0.7로 잡고 시작

- bb1과 bb2의 IoU를 계산해보면 0.7이상인 0.8이 나온다 그러므로 같은 객체라고 취급하여 bb2를 0으로 변경
- bb2는 제거됐으니 bb5부터 또 시작하여 유사한 bb를 제거
5-2 Training
1) RPN
1-1 RPN 단계에서 classiciation고 ㅏregressor 학습을 위해 ancorbox를 positive/negative samples 구분
1-2 데이터셋 구성
- IoU > 0.7 or highest IoU with GT: positive samples
- IoU < 0.3: negative samples (배경)
- Otherwise(0.3~0.7부분): 학습데이터로 사용하지 않음
1-3 Loss
- classification: crossentropy
- regression: MSE
pi*는 인덱스를 가리킴
객체가 있는 인덱스에서만 regression을 수행

2)Region Proposal 이후 Fast RCNN 학습을 위해 positive/negative samples로 구분
2-1 데이터셋 구성
- IoU > 0.5: positive samples → 32개
- IoU < 0.5: negative samples → 96개
- 128개의 samples로 mini-bath 구성
2-2 Loss 함수
- Fast RCNN과 동일
학습과정
RPN과 Fast RCNN 학습을 위해 4 steps alternative training 활용
- Step 1) Imagenet pretrained backbone load + RPN 학습
- Step 2) Imagenet pretrained backbone load + RPN from step 1 + Fast RCNN 학습
- Step 3) Step 2 finetuned backbone load & freeze + RPN 학습
- Step 4) Step 2 finetuned backbone load & freeze + RPN from step 3 + Fast RCNN 학습
-> 학습 과정이 매우 복잡해서, 최근에는 Approximate Joint Training 활용
5-3 Results

5-4 Shortcomings
1) 2000개의 RoI 각각 CNN 통과
2) 강제 Warping, 성능 손실 가능성
3) CNN, SVM classifier, bounding box regression, 따로 학습
4) End-to-End X

'부스트캠프 AI Tech 2기 > 2기 CV P-Stage-Objectdetection' 카테고리의 다른 글
| EfficientDet (0) | 2021.10.02 |
|---|---|
| 1 stage Detectors (0) | 2021.10.01 |
| Neck (0) | 2021.09.30 |
| MMDetection & Detectron2 (0) | 2021.09.29 |
| Object Detection Overview (0) | 2021.09.28 |