
1. 좋은 데이터셋의 선결조건, 가이드라인
1.1 가이드라인이란?
가이드 라인 : 좋은 데이터를 확보하기 위한 과정을 정리해 놓은 문서
좋은 데이터는 되도록 골고루(Raw Data) 모여 있고 일정하게(Ground Truth) 라벨링된 데이터

특이 경우를 발견하고 해당 샘플들을 확보하려고 노력해야 하며, 이를 포함한 라벨링 가이드를 만들어야 한다
- 데이터 구축의 목적
- 라벨링 대상 이미지 소개
- 기본적인 용어 정의
- BBOX, “전사”, “태그" 등등
- Annotation 규칙
- 작업불가 이미지 정의
- 작업불가 영역 (illegibility = True) 영역 정의
- BBOX 작업 방식 정의
- 최종 format
* 보통 가이드라인이라고 할 때는 라벨링에 관한 얘기만 다룬다. 그래서, 가이드라인은 데이터셋 구축 시 실제 레이블링할 사람들에게 규칙 및 주의사항을 전달하는 문서라고 할 수 있다.


가이드라인은 작성시 세가지 요소가 조화롭게 있어야한다
- 특이케이스: 가능하면 특이 케이스가 다 고려된 가이드라인!!
- 단순함: 모든 특이 케이스를 다루는 가이드라인이 너무 장황하면 분량이 너무 많아지고, 작업자들이 다 숙지 못해서 결국 라벨링 노이즈 발생
- 명확함: 동일한 가이드 라인에 대해서 같은 해석이 가능하도록 최대한 명확하게 작성하는 것이 라벨링 노이즈를 줄이는 데에 필수
1.2 학습 데이터셋 제작 파이프라인
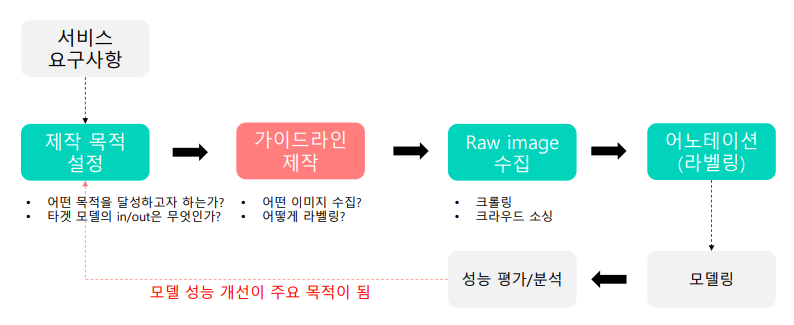
제작 목적 설정
- 어떤 목적을 달성하고자 하는가?
- 타겟 모델의 in/out은 무엇인가?
Q. 모든 영수증? 이마트만? 식당만?
Q. 모든 글씨를 다 인식해야 하나? 메뉴에 관련된 정보만? …
Q. 모델 전체 구조는?
예. 검출기+인식기 혹은 검출기 인식기 따로?, 각각에서 라벨링해야 할 정보는?
-> 이런식으로 필요한 목적을 설정해야한다.
1-2-1 Raw Image 수집 - 크롤링
1) 검색어
- 어떤 결과가 나오는지에 제일 중요한 영향을 주는 것은 “검색어” è 검색어의 집합으로 글자가 등장하는 대부분 상황에 대한 이미지들을 크롤링 할 수 있어야 한다
-> 좋은 키워드 선정 ex)간판
2) 조건
- 이미지 크기는 되도록 큰것(Augmentation을 효율적으로 하기 위함)
- 파일유형중 배경이 가끔 투명한 이미지가 있어 문제를 일으킨다
- 사용권: 상업적으로 사용시 반드시 조건을 걸어서 해당 라이선스를 갖는 이미지만 모이도록

1-2-2 Raw image 수집 - 크라우드 소싱

- 수집용 가이드라인 제공
- Edge case 수집에 유리
- 원하는 특성 명시
- 좋은 예, 나쁜 예를 직접 사람에게 학습시킬 수 있음
- 시간, 비용이 많이 들어 일반적으로 크롤링된 이미지에 추가하는 방식으로 진행
- 구하기 힘든 이미지
- 개인정보, 저작권 이슈에서 자유로움
2. General OCR Dataset 예제로 알아보는 가이드라인 작성법
2.1 개요
1) 가이드라인 제작과정
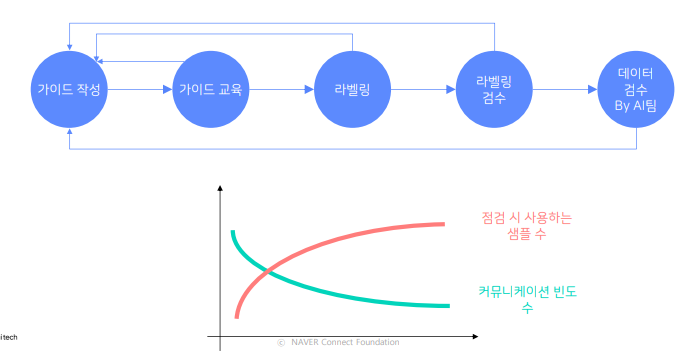
- 라벨링 방식에 대해서 탐색을 많이 해야 하거나, 일반 사람들에게 익숙하지 않는 데이터에 대해 라벨링을 할 경우에는 가이드 작성의 횟수가 높아 가이드 작성/수정/교육에 대한 비용이 크기 때문에 외주보다 차라리 내부에서 인력을 고용해서 진행하는게 효율적일 수 있음
- 가이드라인 versioning이 중요
- 수정 사항을 tracking
- 이후 새로운 가이드를 작성할 때 어느 문서를 기반으로 수정하였는지 기록
- e.g. General OCR 용 가이드(v.1.4) 기반으로 Document Text OCR용 가이드 (v.1.0) 작성
- pilot labeling 및 edge case 대응
- 가이드라인 구축 전에 직접 라벨링을 해보는 것이 필수적
- 이 때 활용할 수 있는 open source tool
- labelme
- label studio
- segments.ai
- cvat
- 기본적인 용어 정의
- Annotation (Labeling) 규칙
- BBOX 작업 방식 정의
- 작업불가 이미지 (HOLD 이미지) 정의
- 작업불가 영역 (illegibility = True) 영역 정의
- 작업 대상 영역
- 최종 format
2.2 노하우
















일관성! 일관성! 일관성!
- 48 Data quality에서 가장 중요한 것은 일관성
- 같은 케이스를 다르게 처리하는 경우가 없도록 하는것.
- 틀려도 모두 같이 틀리면 나중에 프로그래밍적인 방법으로 수정이 가능
- 일관성은 어떻게 확보?
- 단순, 정확한 설명. 객관적으로 measure가 가능하여 누구나 똑같이 이해할 수 있는 지표를 줘야 함
- 가이드 내용이 추가 될 시 기존 다른 내용과의 conflict 가능성을 고려하여야 함
- 이 내용이 추가됨으로써 영향을 받게 되는 다른 지점이 있는지 등
가이드라인의 우선순위
- Annotation 레벨에서 반드시 정확히 레이블링 되어야 할 것이 무엇인지 우선순위를 아는 것이 중요하다.
1. 읽을 수 있는 글자 영역 전부 Points 표시하기
2. Points 표시의 일관성 유지 및 transcription 정확히 하기
3. 글자는 존재하지만 육안상 알아보기 어려운 illegibility=True 영역 (“don’t care”) annotation
4. 각종 태그 - 언어, 글자 진행 방향, 이미지 태그 및 단어 태그
2.3 가이드라인으로 데이터 구축하기

가이드 자체가 잘 동작하고 있는지를 검수
TIP 1. 초기에 소량씩 완성본 받아서 품질을 확인
- 온전한 가이드라인이 나오기 까지는 실험 후 수정의 과정이 여러 번 필요하기 때문에 처음에는 최대한 빠르게 이 iteration을 가져가는 것이 좋다
TIP 2. 작업자 QnA 활용
- 작업자들의 문의 사항이 왔을 때 이 질문이 어떤 가이드라인 때문인지를 확인하여 질문이 나오지 않게 하려면 어떻게 수정해야 할지를 고민한다
TIP 3. 추가 수정을 위한 비용과 시간이 크다면 어느 정도 포기함
- 어느 정도 안고 갈 라벨링 노이즈가 무엇일지 개발팀과 얘기 나눠서 정하면, 가이드라인 별 우선순위가 정해지기 때문에 진행이 훨씬 수월하다
가이드라인 만들기는 끝없는 의사소통과 수정의 연속
1. 충분한 pilot tagging을 바탕으로 가이드 제작
2. 가이드라인 수정 시 versioning 필요, 기존 내용과 충돌 없도록 최소한의 변경만
3. 최대한 명확하고 객관적인 표현을 사용
4. 일관성 있는 데이터가 가장 잘 만들어진 데이터 5. 우선순위를 알고, 필요하다면 포기하는 것도 중요
'부스트캠프 AI Tech 2기 > 2기 CV 데이터제작' 카테고리의 다른 글
| Annotation Tool 소개 (0) | 2021.11.14 |
|---|---|
| 성능 평가 방식 (0) | 2021.11.14 |
| 데이터 소개 (0) | 2021.11.09 |
| Text Detection 소개 (0) | 2021.11.09 |
| 데이터 제작의 중요성 2 (0) | 2021.11.09 |