
1일차
EDA
2일차
Data Set
- 처음 주어진 vanilla data의 변환이 필요하기 때문에 Data Set이 필요하다
전처리 작업에 많은 resource가 소요됨
이미지
- Bounding box
필요 이상으로 많은 정보를 가지고 있기 때문에 crop해준다 - Resize
- 도메인에 따라 형식에 따라 다양한 case가 존재한다

Generalization
- Bias & Variance

- Train / Validation
데이터가 줄어들어 오히려 언더피팅이 되지않나 라고 생각하지만 학습에 이용되지 않은 데이터 셋으로 검증을 해야만 한다.
validation set도 train에 관여해서 일반화 되기때문에 학습이 끝난 이후의 test set도 필요하다. - Data Augmentation
주어진 데이터가 가질 수 있는 경우, 상태의 다양성
문제가 만들어진 배경과 모델의 쓰임새를 살펴서 해당 도메인에 맞는 augmentation을 사용
torchvision.transform
마스크를 낀 채 사진을 찍을경우 뒤집어서도 찍나??
일반적으로 뒤집어서 찍는 경우는없다 그러므로 vertical flip같은 처리는 하지 않는다

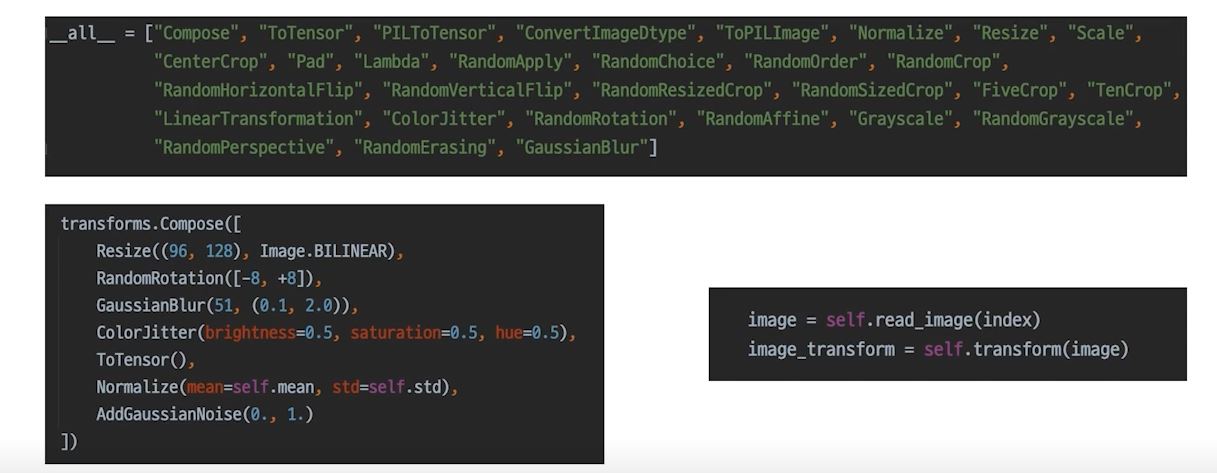
Albumentations
torchvision.transform 보다 더 빠르고 다양하다
항상 좋은 결과를 가져다 주지 않기 때문에, 실험으로 증명해야한다.
Data Generation
- Data Feeding
대상의 상태를 고려하여 적정한 양을준다.
Dataset이 데이터를 불러오는 속도와 Model이 학습하는 속도가 잘 맞아야 효율적으로 학습할 수 있다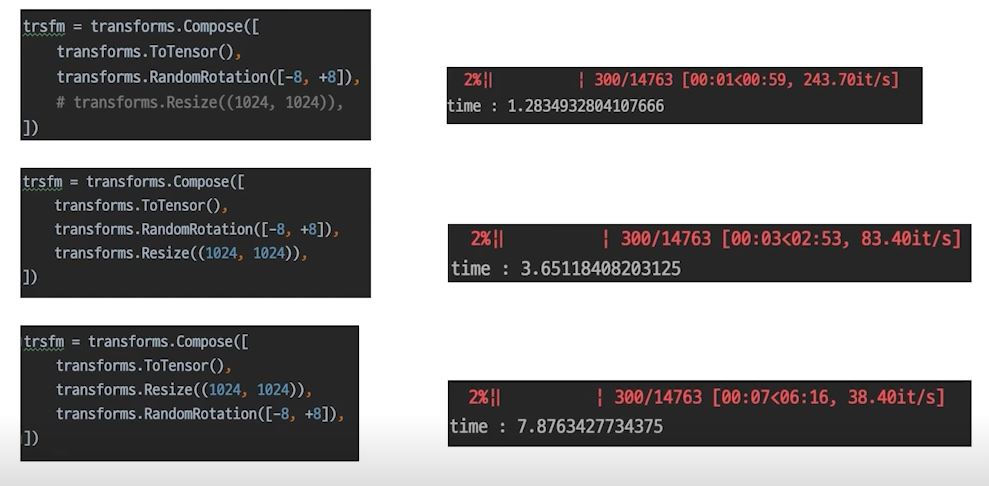
torch.utils.dataloader
Dataloader랑 DataSet은 엄연히 다르기 때문에 재사용을위해 잘 구분해두자


3일차
Model
- pytorch의 모델은 nn.Mudule을 상속받아서 사용한다
- forward: 모델을 그냥 호출해도 실행이되고 .forward()로 실행시켜줘도 실행이된다
- 각각의 nn.Conv2d들도 forward를 지니고있기때문에 이 forward들은 연결이된다
- parameters:
- model.state_dict()
- list(model.parameters())
- 파라미터를 찾아서 잘 안되는부분만 수정할 수 있다
Pretrained Model
ImageNet이라는 서비스가 만들어진 이후에 Vision이 엄청난 속도로 발전하게되었다.
모델 일반화를 위해 매번 수많은 이미지를 학습시키는것이 까다롭고 비효율적

CNN 이미지 모델 구조
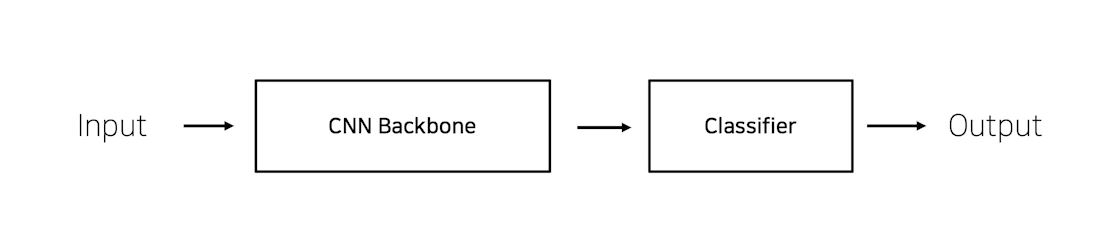
pretrained 모델 불러오기
- 이미지의 pretrained는 실생활에 존재하는 여러개의 이미지를 1000개의 클래스로 분류했음
- 강아지, 고양이, 사과등
- pretraining 할 때 설정했던 문제와 현재의 문제와의 유사성을 고려해야한다
- 구름종류??

Case By Case
- 풀려고하는 학습 데이터가 충분하다
예를들어 자동차를 그냥분류하는게 아니라 자동차 브랜드별로 분류하고 싶다
하지만 pretrained된 모델은 브랜드까지 학습하진 않았을것같다.
즉 다시 학습을 해야 하지만 그렇다 하더라도 pretrained된 모델을 불러와서 시작하는게 좋다.


- 학습데이터가 충분하지 않을 때
pretrained된 모델과 유사한 작업을 할 때는 classifier만 학습해서 사용한다
하지만 유사하지않을경우 데이터도없다면 결과가 무의미할 수 도있다.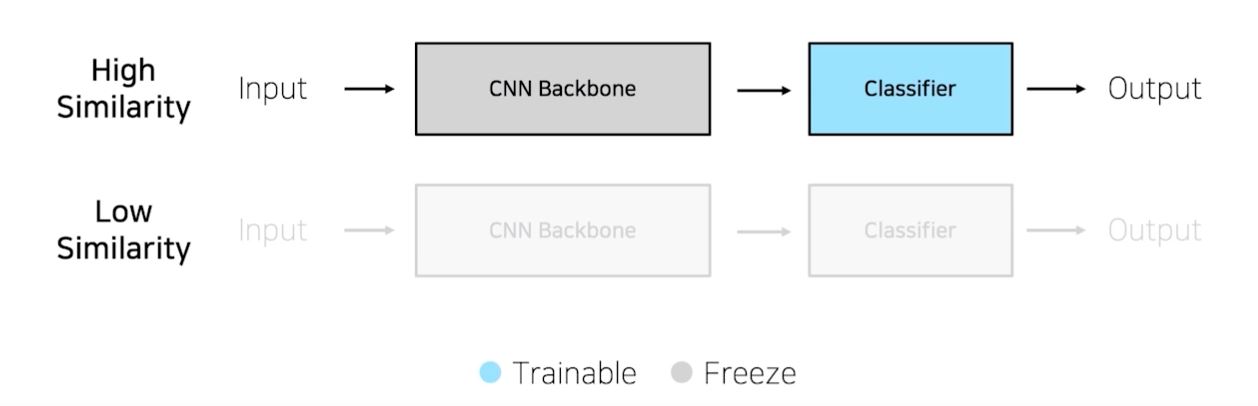
4일차
LOSS
Focal loss
- class imbalance 문제가 있는 경우, 맞춘 확률이 높은 class는 조금의 loss를, 맞춘 확률이 낮은 class는 loss를 훨신 높게 부여
- class가 다양한곳에서 밸런스가 맞지 않은곳에서 사용
Label smoothing loss - class target label을 onehot 표현으로 사용하기보다는 ex_[0,1,0,0,0,0...] 조금 soft하게 표현해서 일반화 성능을 높이기 위함 ex_[0.0025,0.9,0.00012,...]
OPTIMIZER
LR scheduler
학습시에 learning rate를 동적으로 조절
- StepLR
- 특정 step마다 LR 감소
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=2, gamma=01)
- CosineAnnealingLR
- cosine 함수 형태처럼 LR을 급격히 변경
- 변화량을 늘릴경우
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=0)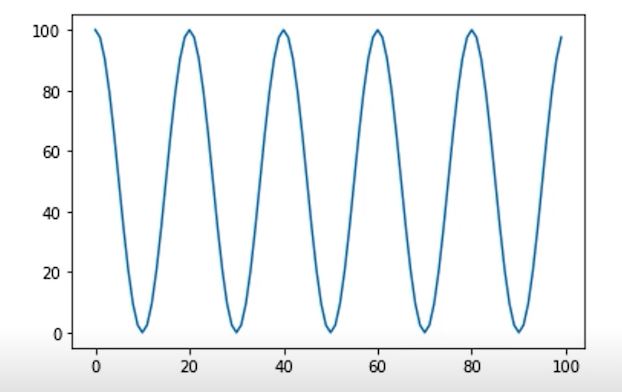
- ReduceLROnPlateau
- 더이상 성능 향상이 없을 때 LR 감소
- 제일 많이 사용됨
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min')
Metric
학습에 직접적으로 영향을 미치지는 않는다
loss만 보고 모델이 잘 학습됐는지를 본다면 loss가 줄더라도 실제 프러덕트로 쓸 수 있는지를 알기위해서는 metric이라는 객관적인 지표가 필요하다.
- Classification
- Accuracy
- F1-score
- precision
- recall
- ROC & AUC
- Regression
- MAE
- MSE
- Ranking
- MRR
- NDCG
- MAP
Metric의 허와 실
왼쪽은 정말 75%라고 생각할 수 있지만 오른쪽 모델은 2000개중 정말 1800개를 맞춰서 90%는 맞지만 다 0으로 찍으면...?
오른쪽보다는 왼쪽처럼 골고루 맞추는게 더 성능이 좋다고 생각이든다.
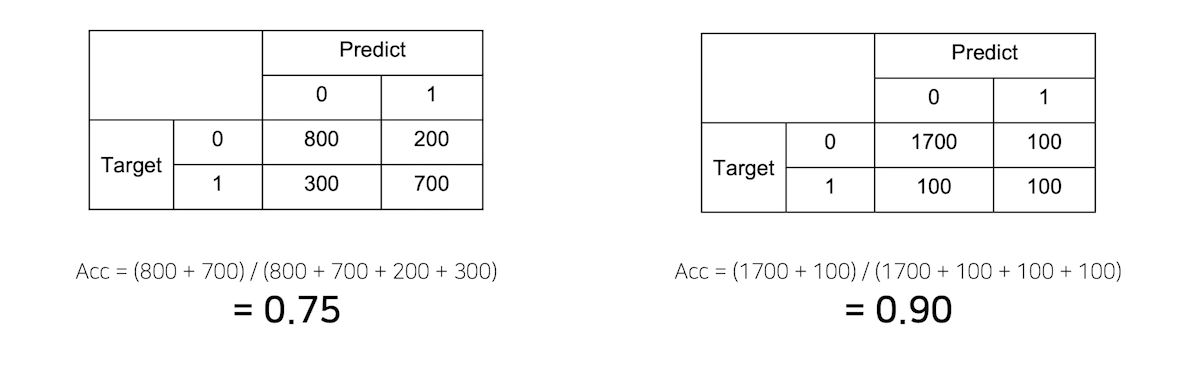
데이터의 상태에 따라 적절한 Metric을 선택하는 것이 필요하다
- accuracy: class별로 데이터의 밸런스가 적절히 분포되어 있을 때
- F1-score: class별로 데이터 밸런스가 좋지 않아서 각 클래스 별로 성능을 잘 낼수있는지 확인해야할 때
Training
준비

- model.train()
- 아래의 함수를 실행하면 모델의 파라미터들 train 가능하게 변경해놓고 학습을 시작해야 한다.
- 이걸 왜 하냐면 Dropout, BatchNorm에 따른 train/eval에 대해 다르게 실행되어야 하는것들이 있기 때문이다
model.train() - optimizer.zero_grad()
- 이전 값의 grad를 초기화 해준다.
- 이걸 해주지 않으면 loss값이 대치가 되는게 아니라 이전 loss와 현재 loss가 grad에 더해진다
optimizer.zero_grad()- loss
- 모델에 input을 넣고 나온 output을 갖고 criterion이라는 함수에 넣어서 loss를 발생시켜 tensor를 만든다.
- criterion이 nn.Module을 상속받고있기 때문에 forward 함수를 가질 수 있다.
- 즉 input부터 시작한 모델의 forward함수와 criterion의 loss함수가 합쳐질 수 있어서 chain으로 연결되어있다.
loss = criterion(outputs, labels)
- Gradient accumulation
loss, optimizer에 대해 제대로 이해했다면 아래와같이 loss를 한번에 처리해 줄 수 있다
NUM_ACCUM = 2
optimizer.zero_grad()
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
outputs = net(inputs)
loss =criterion(outputs, labels) / NUM_ACCUM
loss.backward()
if i%NUM_ACCUM ==0:
optimizer.step()
optimizer.zero_grad()
- checkpoint
직접 짜면된다~
if val_loss < best_val_loss:
print("New best model for val loss! saving the model")
torch.save(model.state_dict(), f"results/{name}/{epoch:03}/_loss_{val_loss:4.2}.ckpt"
best_val_loss = val_loss
if val\_acc < best\_val\_acc:
print("New best model for val loss! saving the model")
torch.save(model.state\_dict(), f"results/{name}/{epoch:03}/_loss_{val\_loss:4.2}.ckpt"
best\_val\_acc = val\_accINFERENCE PROCESS
- model.eval()
- dropout과 batchnorm에대해 영향을 준다
- with torch.no_grad():
- 해당 함수로 감싸서 평가하는 동안에는 set_grad를 False로 체크한다
5일차
Ensemble
- Ensemble
- Model Average
- 서로 다른 모델을이용

- 서로 다른 모델을이용
- Cross validation
- cv라고도 부르며 CV점수가 얼마냐 라고도물어봄

- cv라고도 부르며 CV점수가 얼마냐 라고도물어봄
- k-fold cross validation
- cross validation의 문제점을 해결하기위해 나옴

- cross validation의 문제점을 해결하기위해 나옴
- TestTimeAugmentation(TTA)
- 테스트도 Augmentation을 해서 더 일반화된 테스트를한다

- 테스트도 Augmentation을 해서 더 일반화된 테스트를한다
앙상블은 효과가 확실하지만 그만큼 학습과 추론시간이 배로 소모됨
Hyperparameter Optimization
모델에 있는 시스템의 메커니즘에 영향을 주는 주요 파라미터
- HiddenLayer 개수
- Learning rate
- k-fold
- Loss 파라미터
- Batch size
- Optimizer 파라미터
- Dropout
- Regularization
Optuna
'부스트캠프 AI Tech 2기 > 2기 P-Stage' 카테고리의 다른 글
| P-Stage 마스크 image classification (0) | 2021.09.04 |
|---|