
AlexNet과 VGG Net을 통해 더 깊은 네트워크가 더 좋은 성능을 보여준다는것을 확인했다.
하지만 더 깊이 쌓을수록 Gradient vanishing/exploding 현상이 발생한다.
과거에는 모델의 표현력이 과하게 좋아져서 Overfitting이 발생할 것이다 라고 예측했지만, Degradation problem이라는 걸로 확인됐다
1. Google Net
구글넷은 레이어를 깊게 쌓는게 아니라 같은 레벨에서 다양하게 쌓는 구조
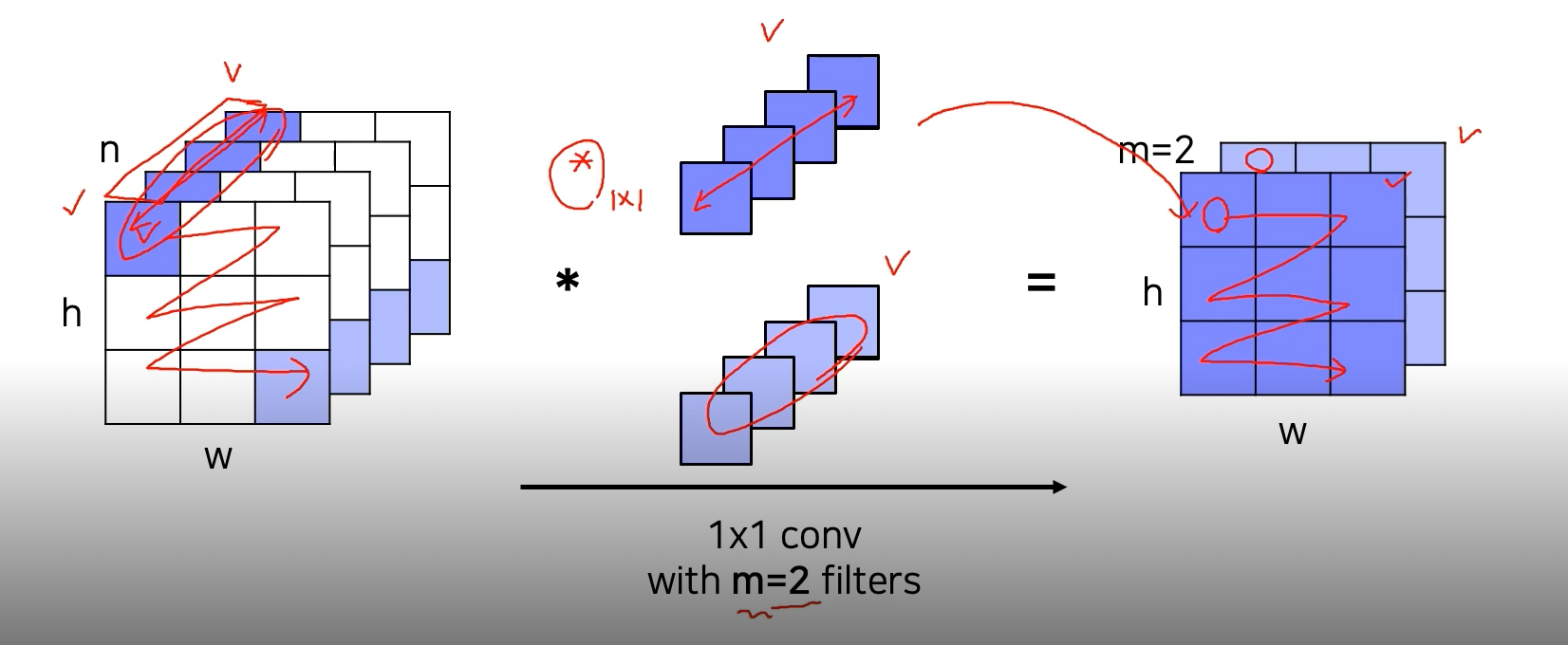
1X1 Conv를 통해 데이터를 압축해서 계산해야하는 양을 줄였다.
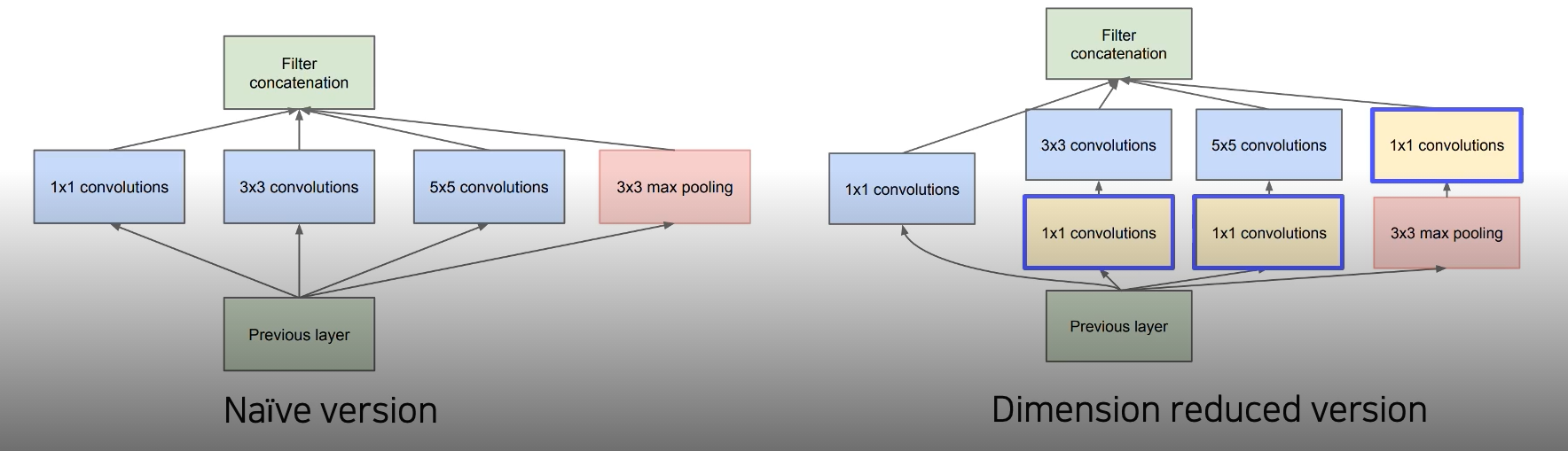
1X1 Convolution
필터의 수만큼 출력채널이 생성된다
공간 크기는 변하지 않고 채널의 수만 변한다
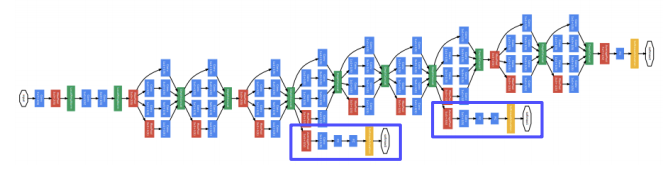
구글넷은 depth가 깊어서 Gradient vanishing 현상이 발생하기 때문에 Output 근처는 학습이 잘 되지만 Output과 멀어진 부분은 학습이 잘 되지 않는 문제가 발생한다.
그래서 아래의 블록된 곳을 통해 Gradient를 중간중간에 주입해준다(Auxiliary Classifier)
하단의 Auxiliary Classifier 부분은 학습시에만 사용하고 테스트때에는 제거한다.
2. ResNet
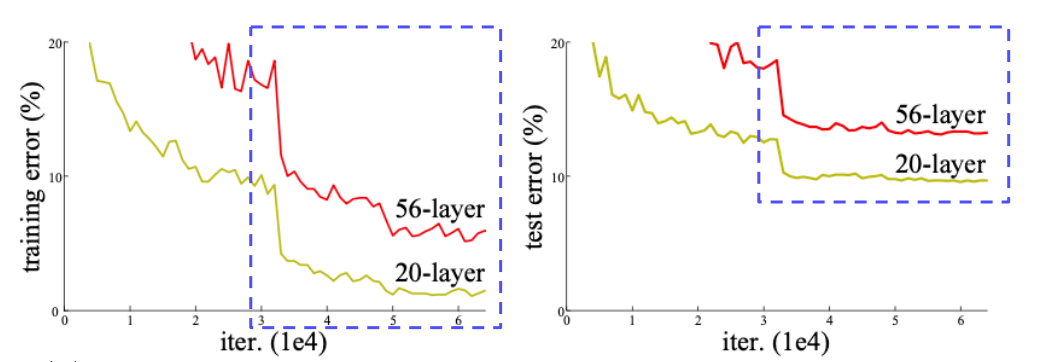
레이어가 깊어질수록 성능이 좋아진다는 것을 증명한 첫 논문
20 layer가 56 layer보다 성능이 더 좋게 나온다
만약! 56 layer의 test error가 20 layer보다 더 높게 나오고 Overfitting 되었다고 말하게 된다면, 56 layer의 train error가 월등히 낮아야한다. (train data에 대해 과적합 되었으니까)
하지만 그렇지 않기 때문에 이 문제는 Overfitting이 아니라 optimization 문제라고 보고있다.(gradient vanishing 등)
Short cut connection (Residual Connection)
- Short cut을 이용해서 자기자신을 잊지 않도록 노력하지 않아도 되게 한다
- Back propagation을 할 때에도 관통하는 gradient의 흐름도 허락이 되기 때문에 옆으로 돌아와서 graident vanishing문제를 해결할 수 있다 ( 아래의 레이어도 학습가능)
![]()

Residual block은 다양한 경로를 통해 layer가 학습이 가능하다
한개의 블럭이 생길때 마다 2^2만큼 경우의수가 늘어난다
왼쪽처럼 레이어를 사이사이 거치지 않고 loss를 내려주면 오른쪽의 그림처럼 볼 수 있다.
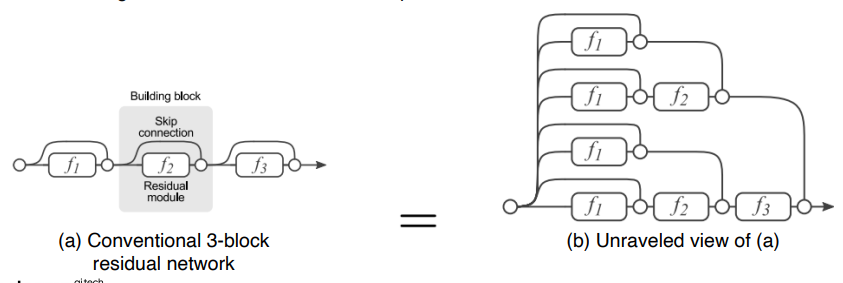
간단하게 요약하면 레이어가 쌓이면서 해상도는 줄어들고 채널의수는 증가한다.

3. DenseNet
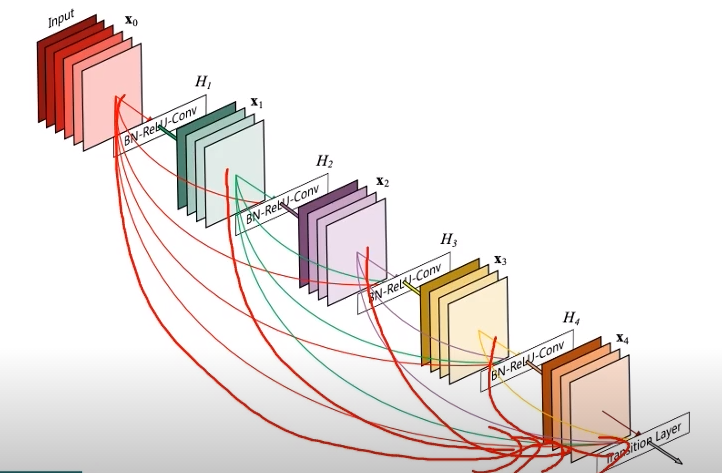
- Resnet에서는 skip connection을 통해서 전달된 identity 맵핑을 더했지만 dense net은 channel 축으로 concatnation하게 설계됨
- 이전의 모든 출력들을 이어주게끔 Dense하게 설계됨
- 상위 레이어에서도 하위 레이어의 특징을 재활용할수있는 기회 제공
- DenseNet은 short connection 방법을 바탕으로, 연속적으로 나오는 각각의 layer를 모두 연결하는 방법을 사용
4. SENet
- depth를 높이거나 connection을 새로하는게 아니라 현재 주어진 activation간의 관계가 더 명확해질수있도록 채널간의 관계를 모델링하고 중요도를 파악해서 중요한 특징을 attention하게끔 만들어줌
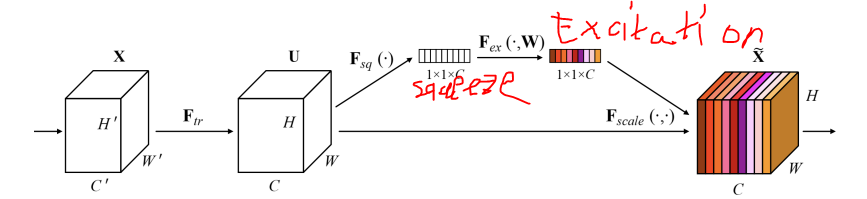
- squeeze: global average pooling을 통해서 각 채널의 공간정보를 없애고 분포를구한다.
- excitation:
- 채널간의 연관성을 통해서 attention 스코어를 생성한다.
- 채널별로 한개씩존재
- 중요도가 떨어지는채널은 값을 낮추고 높다고 생각되는건 강조한다.
순서
- squeeze 과정을 통해 global average pooling을 하여 1x1xChannel로 압축한다.
- 압축한 데이터로 Excitation을 거쳐, Channel 사이의 Feature들에 대한중요도를 Recalibaration(재조정)한다.
- 재조정된 중요도를 담은 Feature를 원래 Feature Map에 곱해주어 중요도가 학습된 새로운 Feature Map을 생성
- 색깔은 각 Feature의 0~1까지의 중요도를 나타냄
- 위의 과정으로 feature map을 압축, 재조정한다.
- 이
- 5. EfficientNet
- 아래의 b,c,d의 경우 성능이 좋아졌기 때문에 이 세개를 합쳐서 e(compound scaling)을 하게됨

6. Deformable Convolution
- 사람이나 동물들의 팔다리의 위치가 상대적으로 바뀌기 때문에 이런 방법이 제안됨
![]()

-> 간단하면서도 성능이 좋은 VGG Net, Res Net이 backbone network로 가장 많이 사용됨
'부스트캠프 AI Tech 2기 > 2기 CV U-Stage' 카테고리의 다른 글
| CNN Visualization (0) | 2021.09.13 |
|---|---|
| Object Detection (0) | 2021.09.10 |
| Semantic Segmentation (0) | 2021.09.09 |
| Annotation Data Efficient Learning (0) | 2021.09.06 |
| CV의 DL 발전(1) (0) | 2021.09.06 |
AlexNet과 VGG Net을 통해 더 깊은 네트워크가 더 좋은 성능을 보여준다는것을 확인했다.
하지만 더 깊이 쌓을수록 Gradient vanishing/exploding 현상이 발생한다.
과거에는 모델의 표현력이 과하게 좋아져서 Overfitting이 발생할 것이다 라고 예측했지만, Degradation problem이라는 걸로 확인됐다
1. Google Net
구글넷은 레이어를 깊게 쌓는게 아니라 같은 레벨에서 다양하게 쌓는 구조
1X1 Conv를 통해 데이터를 압축해서 계산해야하는 양을 줄였다.
1X1 Convolution
필터의 수만큼 출력채널이 생성된다
공간 크기는 변하지 않고 채널의 수만 변한다
구글넷은 depth가 깊어서 Gradient vanishing 현상이 발생하기 때문에 Output 근처는 학습이 잘 되지만 Output과 멀어진 부분은 학습이 잘 되지 않는 문제가 발생한다.
그래서 아래의 블록된 곳을 통해 Gradient를 중간중간에 주입해준다(Auxiliary Classifier)
하단의 Auxiliary Classifier 부분은 학습시에만 사용하고 테스트때에는 제거한다.
2. ResNet
레이어가 깊어질수록 성능이 좋아진다는 것을 증명한 첫 논문
20 layer가 56 layer보다 성능이 더 좋게 나온다
만약! 56 layer의 test error가 20 layer보다 더 높게 나오고 Overfitting 되었다고 말하게 된다면, 56 layer의 train error가 월등히 낮아야한다. (train data에 대해 과적합 되었으니까)
하지만 그렇지 않기 때문에 이 문제는 Overfitting이 아니라 optimization 문제라고 보고있다.(gradient vanishing 등)
Short cut connection (Residual Connection)
- Short cut을 이용해서 자기자신을 잊지 않도록 노력하지 않아도 되게 한다
- Back propagation을 할 때에도 관통하는 gradient의 흐름도 허락이 되기 때문에 옆으로 돌아와서 graident vanishing문제를 해결할 수 있다 ( 아래의 레이어도 학습가능)
![]()
Residual block은 다양한 경로를 통해 layer가 학습이 가능하다
한개의 블럭이 생길때 마다 2^2만큼 경우의수가 늘어난다
왼쪽처럼 레이어를 사이사이 거치지 않고 loss를 내려주면 오른쪽의 그림처럼 볼 수 있다.
간단하게 요약하면 레이어가 쌓이면서 해상도는 줄어들고 채널의수는 증가한다.
3. DenseNet
- Resnet에서는 skip connection을 통해서 전달된 identity 맵핑을 더했지만 dense net은 channel 축으로 concatnation하게 설계됨
- 이전의 모든 출력들을 이어주게끔 Dense하게 설계됨
- 상위 레이어에서도 하위 레이어의 특징을 재활용할수있는 기회 제공
- DenseNet은 short connection 방법을 바탕으로, 연속적으로 나오는 각각의 layer를 모두 연결하는 방법을 사용
4. SENet
- depth를 높이거나 connection을 새로하는게 아니라 현재 주어진 activation간의 관계가 더 명확해질수있도록 채널간의 관계를 모델링하고 중요도를 파악해서 중요한 특징을 attention하게끔 만들어줌
- squeeze: global average pooling을 통해서 각 채널의 공간정보를 없애고 분포를구한다.
- excitation:
- 채널간의 연관성을 통해서 attention 스코어를 생성한다.
- 채널별로 한개씩존재
- 중요도가 떨어지는채널은 값을 낮추고 높다고 생각되는건 강조한다.
순서
- squeeze 과정을 통해 global average pooling을 하여 1x1xChannel로 압축한다.
- 압축한 데이터로 Excitation을 거쳐, Channel 사이의 Feature들에 대한중요도를 Recalibaration(재조정)한다.
- 재조정된 중요도를 담은 Feature를 원래 Feature Map에 곱해주어 중요도가 학습된 새로운 Feature Map을 생성
- 색깔은 각 Feature의 0~1까지의 중요도를 나타냄
- 위의 과정으로 feature map을 압축, 재조정한다.
- 이
- 5. EfficientNet
- 아래의 b,c,d의 경우 성능이 좋아졌기 때문에 이 세개를 합쳐서 e(compound scaling)을 하게됨
6. Deformable Convolution
- 사람이나 동물들의 팔다리의 위치가 상대적으로 바뀌기 때문에 이런 방법이 제안됨
![]()
-> 간단하면서도 성능이 좋은 VGG Net, Res Net이 backbone network로 가장 많이 사용됨
'부스트캠프 AI Tech 2기 > 2기 CV U-Stage' 카테고리의 다른 글
| CNN Visualization (0) | 2021.09.13 |
|---|---|
| Object Detection (0) | 2021.09.10 |
| Semantic Segmentation (0) | 2021.09.09 |
| Annotation Data Efficient Learning (0) | 2021.09.06 |
| CV의 DL 발전(1) (0) | 2021.09.06 |