부스트캠프 AI Tech 2기/2기 CV U-Stage
Image Captioning
모플로
2021. 9. 17. 22:57
반응형
Image captioning은 이미지를 입력하여, 이미지를 가장 잘 설명하는 문장을 출력하는 task입니다.
Encoder 부분
- pretrained된 모델을 불러와서 poolling과 linear를 제거하여 사용
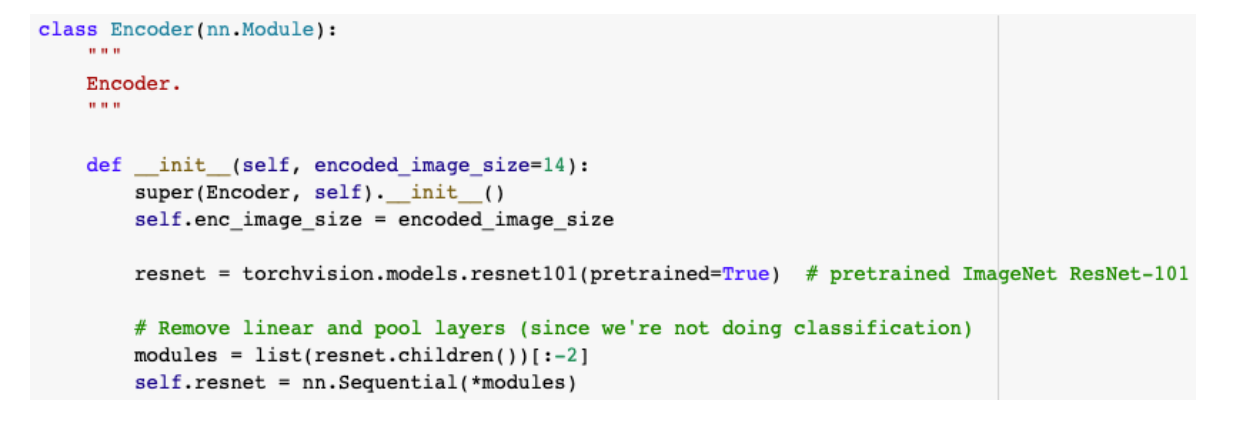
Decoder 부분
- 스타트토큰이 디코더에 들어가고
- 이전에 출력된 정보와 attention정보(어디를 봐야하는지)를 input으로 넣어서 사용
- RNN은 굉장히 많은 word class를 가진 classification이다
이런 classification을 사용하면 'a'라는 값보다 더 나은 값이여도 이미 앞단계에서 버렸기때문에 아쉬운 상황이 발생한다
그럴 때 사용하는게 Beam search 기술이다
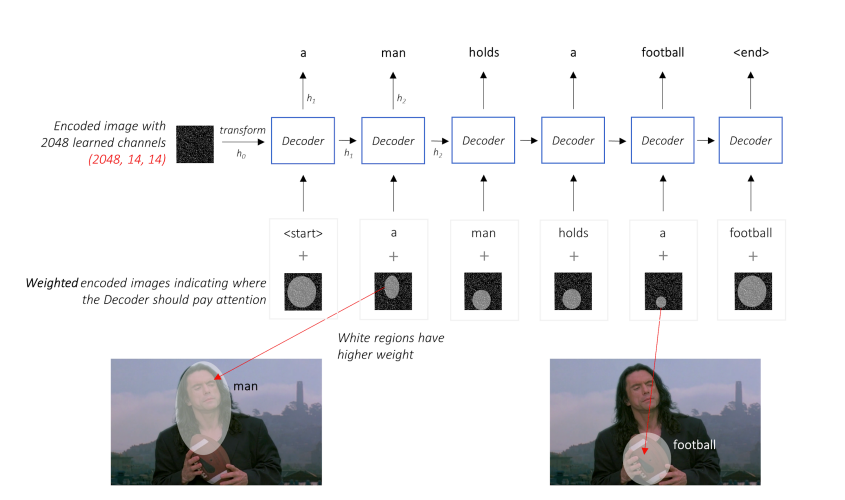
Bean Search는 top 1이아닌 top k개를 골라서 사용한다.
처음 3개의 데이터가 2번째 레이어로 넘어가면 2번째 레이어에서는 3X3으로 9개의 조합이 나온다.
9개의 조합을 점수를 매겨서 top 3만 또 다음 layer로 넘겨준다.
즉 3개까지는 여지를 계속주면서 다음 값을 추측한다.
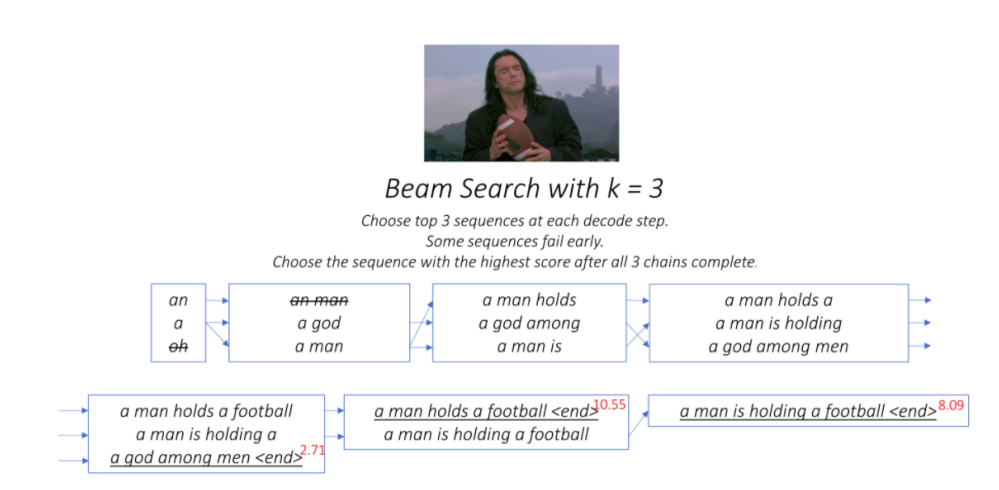
요약

반응형