
총 10개의 trash label을 대상으로 objectdetection 수행
프로젝트에 사용된 기술
-
- mmdetection lib
진행 요약
1주차
이번 대회때 live template을 구성하고 싶은 마음에 팀원들이 사용할 template을 만들어봤다.
해당 template을 customize하여 구성했다.
https://github.com/victoresque/pytorch-template
GitHub - victoresque/pytorch-template: PyTorch deep learning projects made easy.
PyTorch deep learning projects made easy. Contribute to victoresque/pytorch-template development by creating an account on GitHub.
github.com
2주차
1주차의 포부가 나의 실력 부족으로 이루어지지 않았다.
2주차에는 mmdetection에 sweeps를 적용시키자 라는 포부를 갖고있었는데, 결국 코드를 짰지만 python의 변수를 동적으로 생성시키는 방법을 몰라서 완벽히 적용시키지는 못했다.
이 부분은 fs를 써서 동적으로 파이썬 파일을 만드는 방법으로 해야하나?
혹은 변수를 동적으로 생성하거나 변수명을 동적으로 바꾸는방법을 찾아봐야겠다
그 외의 learningrate등은 1주차에 만든 live template에 있는 Custom Args를 사용하여 변수의 값을 편하게 바꿀 수 있었다.
2주차에는
팀원들과 Github의 Project와 wandb를 사용하여 현황을 공유했다
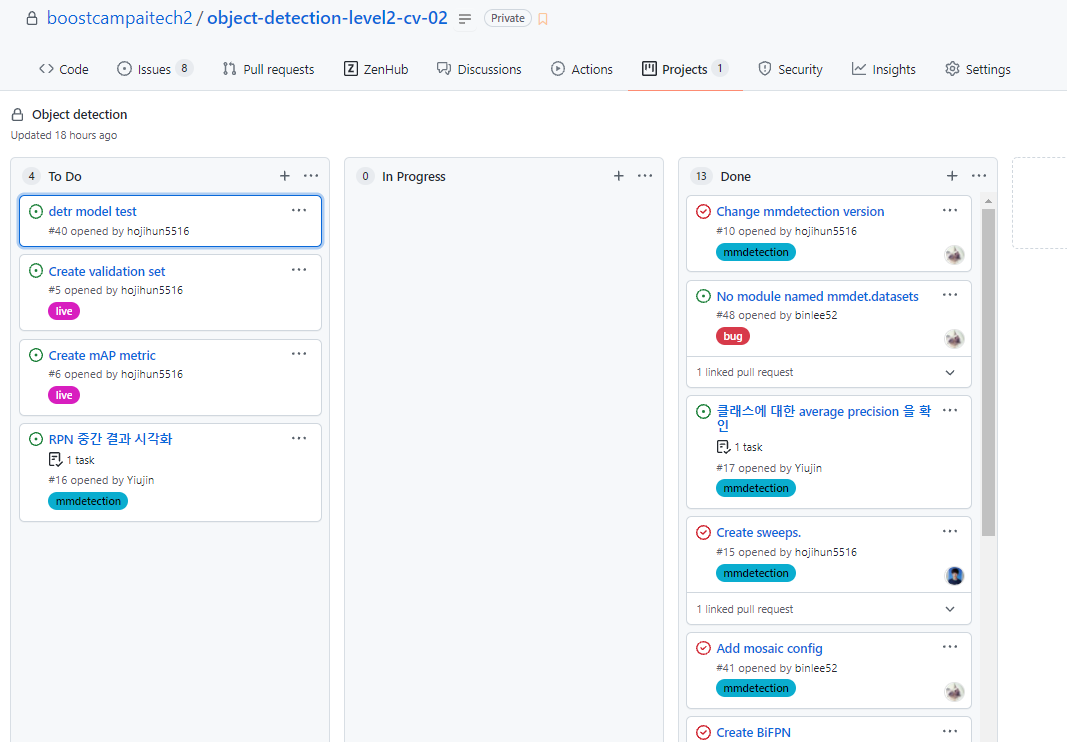
같은 lib을 사용하다보니 wandb에 쌓이는 로그의 키값도 같았다.
이부분을 커스터마이징 하고싶어서 mmcv를 수정했는데 path 에러가 생겨서 계속 실패했다.
이 부분은 setup.py를 직접 손봐야한다
다음 대회(Segmentation) 때 시도해볼 예정
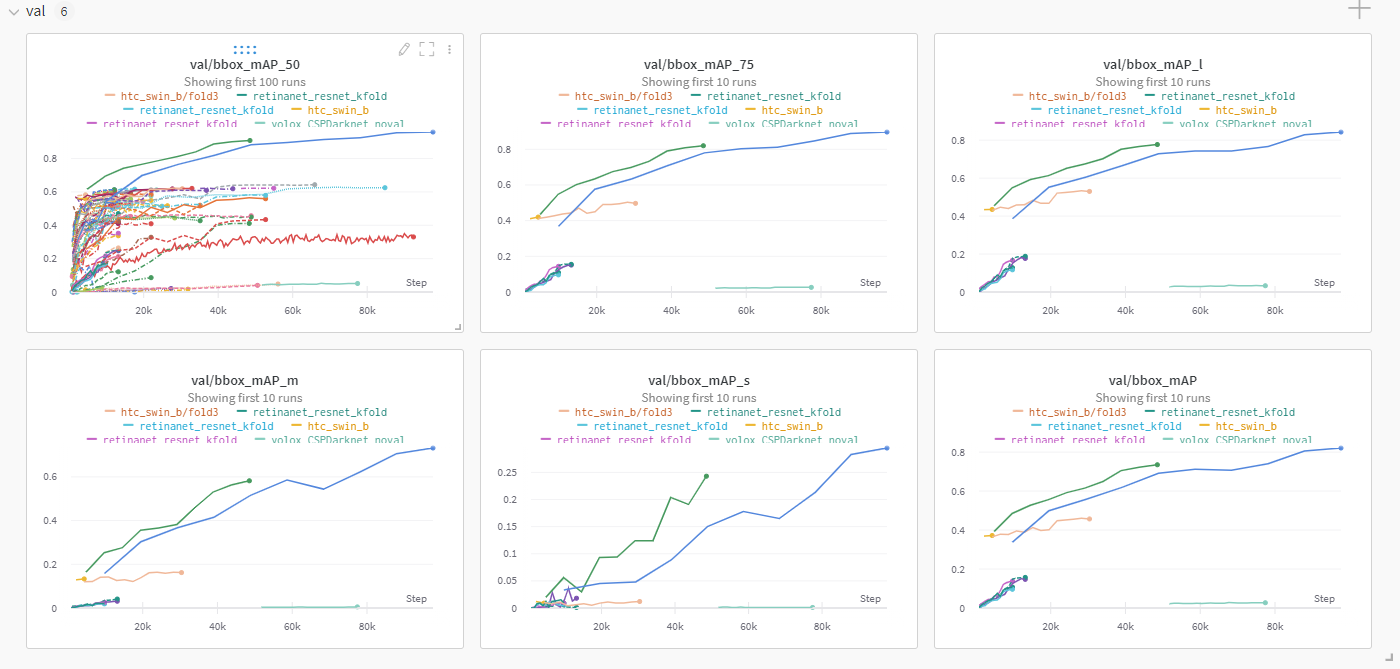
3주차
사용해보지 못한 모델이 많아서 조금씩 더 실험해보고, K-fold와 pseudo labeling을 했다.
pseudo labeling을 한 모델은 높은 점수가 나왔다.
이 방법은 저번 classification에서도 사용됐었는데 금지된 대회도 있다고 하니 유의해야겠다.
가장 성능이 좋은모델을 사용하여 test 데이터를 inference한 다음 결과로 나온 데이터를 추가로 사용하여 train하는 방법이다.
결과 요약
github과 wandb를 사용함으로써 팀원이 어떤 사항을 하고있는지 어떤 모델에 집중하고있는지를 알 수 있어서 편하고 좋았다.
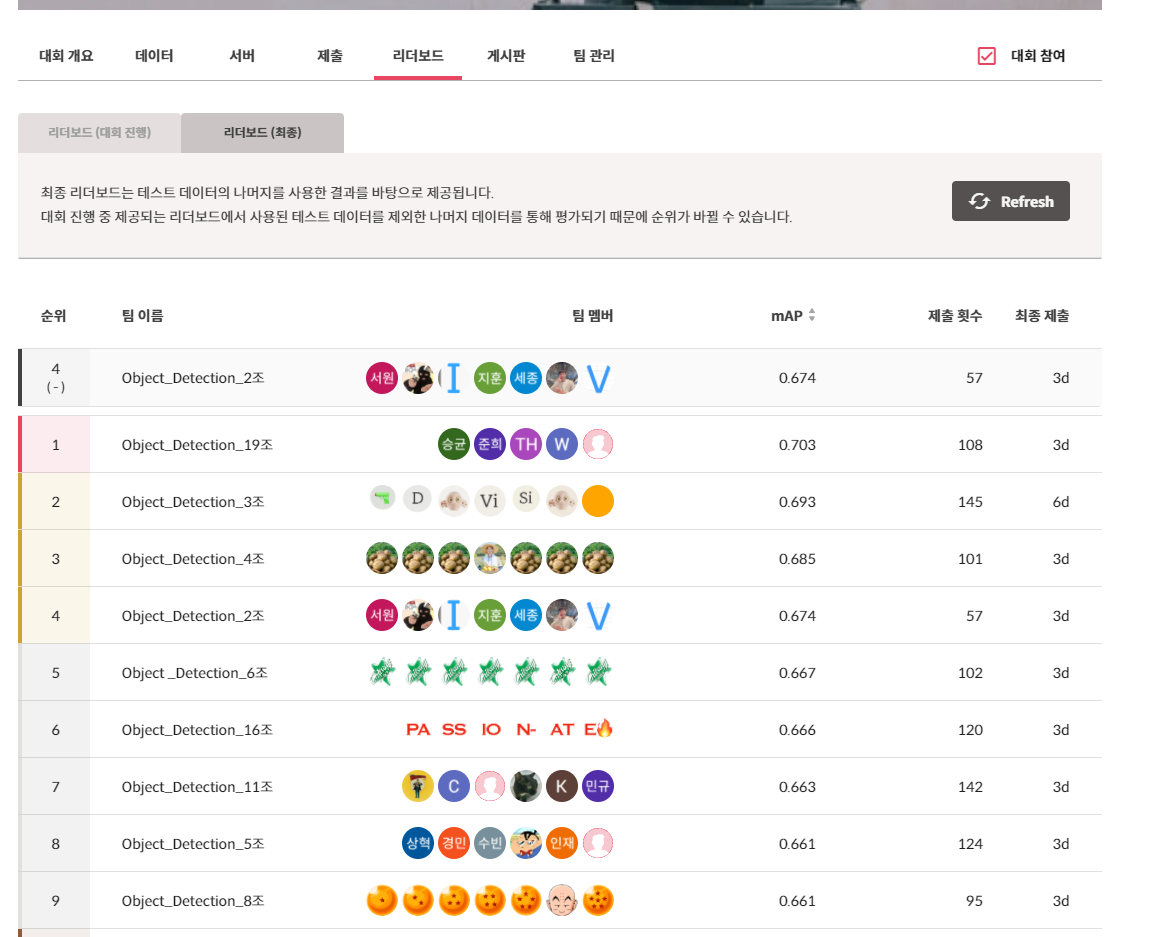
여러 모델 output을 ensemble하여 우리팀은 19개팀중 4등을 기록했다.
ensemble하는 모델을 전략적으로 하고싶었는데, 시도는 해봤으나 좋지 못했다.
무작정 모델을 많이 넣은게 대체로 좋았다
느낀점
One-Stage_Model인 Yolo와 DETR에 대해 아쉬움이 조금 남는다.
1,2등 팀들에게 물어보니 한개의 모델을 50시간 넘게 training시켰다는 이야기를 듣고, 분명히 나는 40에포크정도 가면 overfitting되었다고 생각했는데 그게 아니였나보다.
또한 Yolo같은 경우는 Adam보다 SGD가 더 빠르게 global minimum을 찾아간다는 것을 확인했다.
항상 Adam이 좋다는 선입견을 깰 수 있었던 실험이였다.
ensemble하는 기준을 잡고싶다
다음 Segmentation할 때에는 제대로된 EDA부터 시작할 예정이다.
EDA를 하고 Data Split부터 한 다음에 모델링을 할 것이다.
팀별 소감문
'부스트캠프 AI Tech 2기 > 2기 CV P-Stage-Objectdetection' 카테고리의 다른 글
| Ready for Competition (0) | 2021.10.08 |
|---|---|
| Advanced Object Detection 2 (0) | 2021.10.06 |
| Advanced Object Detection 1 (0) | 2021.10.05 |
| EfficientDet (0) | 2021.10.02 |
| 1 stage Detectors (0) | 2021.10.01 |
총 10개의 trash label을 대상으로 objectdetection 수행
프로젝트에 사용된 기술
-
- mmdetection lib
진행 요약
1주차
이번 대회때 live template을 구성하고 싶은 마음에 팀원들이 사용할 template을 만들어봤다.
해당 template을 customize하여 구성했다.
https://github.com/victoresque/pytorch-template
GitHub - victoresque/pytorch-template: PyTorch deep learning projects made easy.
PyTorch deep learning projects made easy. Contribute to victoresque/pytorch-template development by creating an account on GitHub.
github.com
2주차
1주차의 포부가 나의 실력 부족으로 이루어지지 않았다.
2주차에는 mmdetection에 sweeps를 적용시키자 라는 포부를 갖고있었는데, 결국 코드를 짰지만 python의 변수를 동적으로 생성시키는 방법을 몰라서 완벽히 적용시키지는 못했다.
이 부분은 fs를 써서 동적으로 파이썬 파일을 만드는 방법으로 해야하나?
혹은 변수를 동적으로 생성하거나 변수명을 동적으로 바꾸는방법을 찾아봐야겠다
그 외의 learningrate등은 1주차에 만든 live template에 있는 Custom Args를 사용하여 변수의 값을 편하게 바꿀 수 있었다.
2주차에는
팀원들과 Github의 Project와 wandb를 사용하여 현황을 공유했다
같은 lib을 사용하다보니 wandb에 쌓이는 로그의 키값도 같았다.
이부분을 커스터마이징 하고싶어서 mmcv를 수정했는데 path 에러가 생겨서 계속 실패했다.
이 부분은 setup.py를 직접 손봐야한다
다음 대회(Segmentation) 때 시도해볼 예정
3주차
사용해보지 못한 모델이 많아서 조금씩 더 실험해보고, K-fold와 pseudo labeling을 했다.
pseudo labeling을 한 모델은 높은 점수가 나왔다.
이 방법은 저번 classification에서도 사용됐었는데 금지된 대회도 있다고 하니 유의해야겠다.
가장 성능이 좋은모델을 사용하여 test 데이터를 inference한 다음 결과로 나온 데이터를 추가로 사용하여 train하는 방법이다.
결과 요약
github과 wandb를 사용함으로써 팀원이 어떤 사항을 하고있는지 어떤 모델에 집중하고있는지를 알 수 있어서 편하고 좋았다.
여러 모델 output을 ensemble하여 우리팀은 19개팀중 4등을 기록했다.
ensemble하는 모델을 전략적으로 하고싶었는데, 시도는 해봤으나 좋지 못했다.
무작정 모델을 많이 넣은게 대체로 좋았다
느낀점
One-Stage_Model인 Yolo와 DETR에 대해 아쉬움이 조금 남는다.
1,2등 팀들에게 물어보니 한개의 모델을 50시간 넘게 training시켰다는 이야기를 듣고, 분명히 나는 40에포크정도 가면 overfitting되었다고 생각했는데 그게 아니였나보다.
또한 Yolo같은 경우는 Adam보다 SGD가 더 빠르게 global minimum을 찾아간다는 것을 확인했다.
항상 Adam이 좋다는 선입견을 깰 수 있었던 실험이였다.
ensemble하는 기준을 잡고싶다
다음 Segmentation할 때에는 제대로된 EDA부터 시작할 예정이다.
EDA를 하고 Data Split부터 한 다음에 모델링을 할 것이다.
팀별 소감문
'부스트캠프 AI Tech 2기 > 2기 CV P-Stage-Objectdetection' 카테고리의 다른 글
| Ready for Competition (0) | 2021.10.08 |
|---|---|
| Advanced Object Detection 2 (0) | 2021.10.06 |
| Advanced Object Detection 1 (0) | 2021.10.05 |
| EfficientDet (0) | 2021.10.02 |
| 1 stage Detectors (0) | 2021.10.01 |