
반응형
Optimization
important concepts in optimization
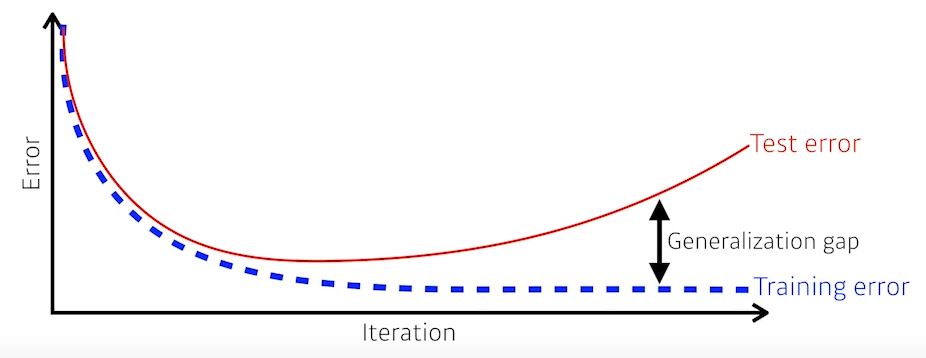
- Generalization
- 일반화 성능을 높인다.
- generalization performance가 좋다는 말은 Trainerror와 Testerror의 차이가 작다는 말이다.
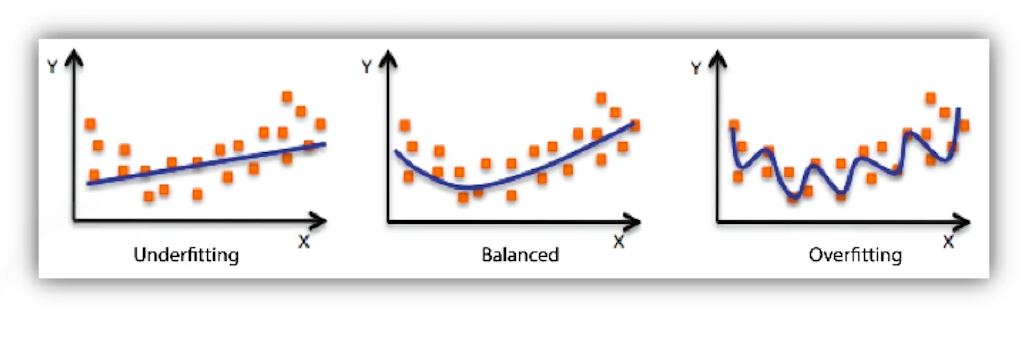
- Overfitting and Underfitting
- Overfitting: 트레이닝 데이터에만 잘 맞고 테스트 데이터에대해 잘 동작하지 않음.
- Underfitting: 네트워크가 너무 간단하거나 학습을 제대로 하지 못해서 트레이닝도 잘 맞추지못함
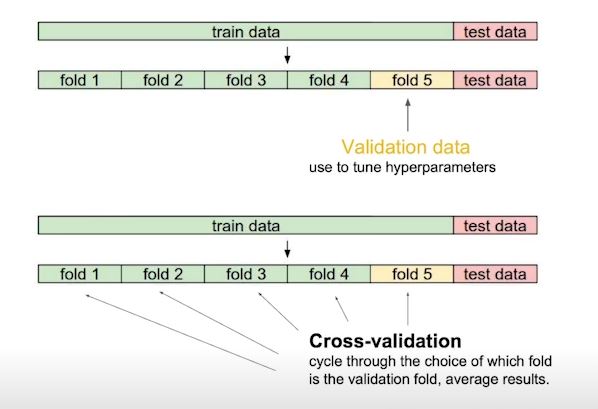
- Cross Validation
- k-fold validation 이라고도 함
- train data를 k개로 나누어서 k-1개로 train하고 나머지 1개로 validation을 함
- 이때 test data는 어떤식(cross-validation, hyper parameter searching등)으로도 활용하면 안된다
- cross validation을 통해 최적의 파라미터를 찾고 하이퍼파라미터를 고정하고 모든 데이터를 다 사용해서 마지막 학습을한다.
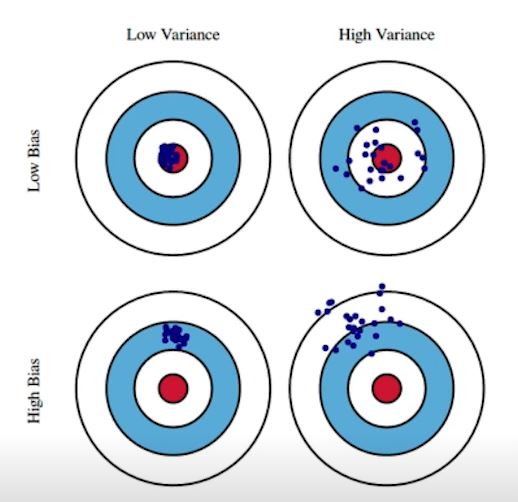
- Bias_variance
- Bias가 낮으면 True target과 유사하다
- Bias가 높으면 mean값에서 벗어난다
- Low Variance는 입력이 들어왔을때 출력이 많이 달라지지 않음
- High Variance는 입력이 들어왔을때 출력이 많이 달라짐 -> overfitting가능성이 커짐
- Bias and Variance trade off
cost = bias**2 + variance + noise- bias를 줄이면 variance가 높아질 가능성이 있다.
- 학습데이터에 noise가 껴있으면 bias와 variance를 둘다 줄이기 힘들다.
- Bootstrapping
- 학습데이터가 고정되어 있을 때 그안에서 subsampling을 통해 여러개의 모델을 만들어서(학습데이터 100개가 있으면 800개씩 사용 등) 무언가(평균 등)를 하겠다.
- Bagging vs Boosting
- Bagging(앙상블)
- 학습데이터를 여러개로 쪼개서 Boot Strapping을 한다
- 여러모델로 아웃풋이 나오면 아웃풋으로 평균을 내거나 voting을 함
- 이렇게 만든 결과가 전체데이터를 학습한것보다 좋을 경우가 많다.
- Boosting:
- 여러개의 weak learner로 하나의 strong learner를 만든다.

- 여러개의 weak learner로 하나의 strong learner를 만든다.
Gradient Descent Method
- SGD
- gradient를 한번 구해서 업데이트하는 것을 계속 반복
- learning rate를 적절히 잡는것이 중요하다.
- Minibatch Gradient Descent
- batchsize를 사용해서 gradient를 업데이트한다
- Batch Gradient Descent:
- 모든데이터를 갖고 loss의 평균을 사용해서 업데이트
-> 대부분 minibatch를 사용한다 (배치사이즈가 작으면 generalize performance가 좋아진다)
- Momentum:
- B라는 하이퍼파라미터를 사용해서 미분된 값을 그대로 쓰지않고 이전값을 같이 활용
- 한번 흘러간 방향으로 gradient를 어느정도 유지시켜줌
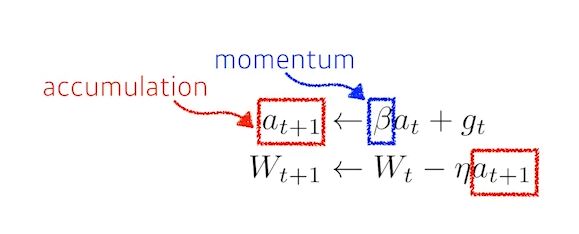
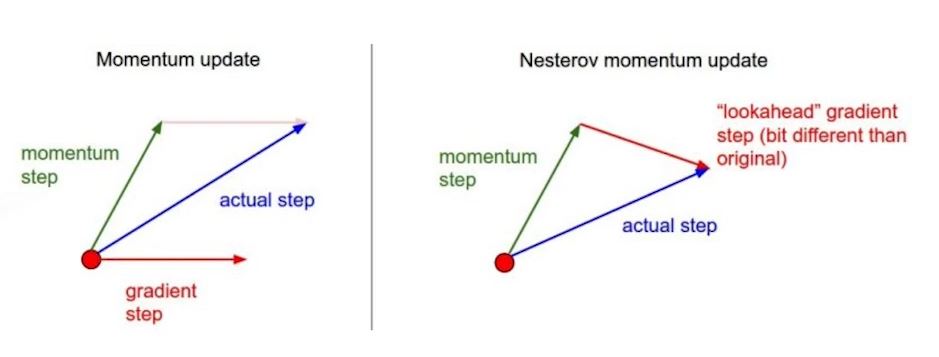
- NAG(Nesterov Accelerate Gradient)
- a라고불리는 현재정보가 있으면 가보고 간 곳에서 gradient를 계산하고 accumulate를 계산한다.
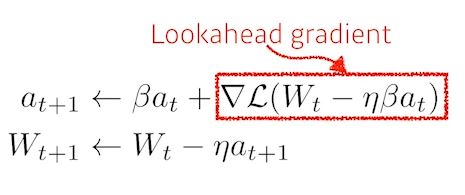
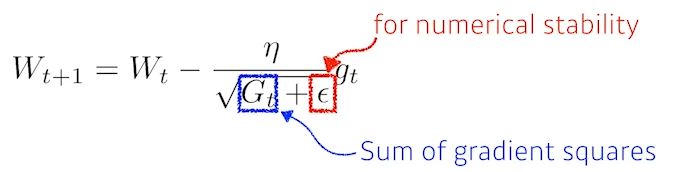
- Adagrad
- 지금까지 많이 변화시킨 파라미터는 적게 변화시키고, 적게 변화시킨 파라미터는 많이 변화시킨다
- 학습하면 할수록 G가 커지면서 분모가 커짐 -> 학습이 안됨
- Adadelta
- Adagrad의 문제점을 보안한다.
- Learningrate가 없고 잘 쓰이지않음...
- RmsProp
- 기울기를 단순 누적하지않고 지수 가중 이동평균을 사용하여 최신 기울기들이 더 크게 반영되도록 한다
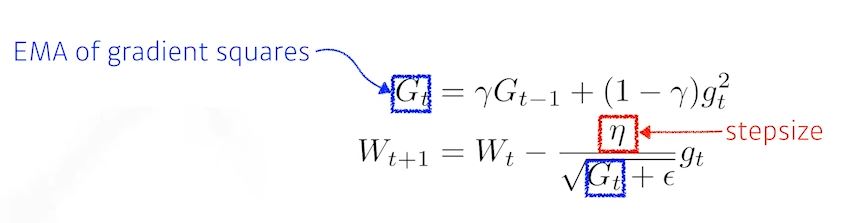
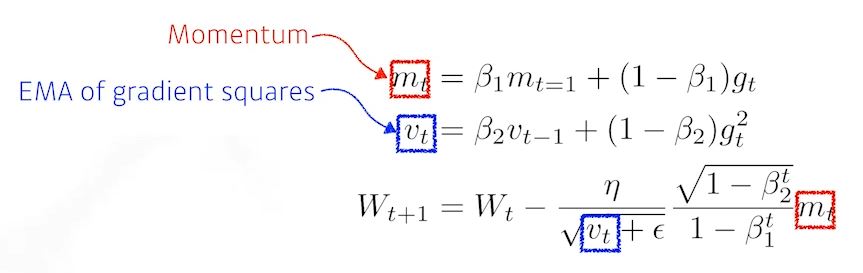
- Adam(Adapted moment Estimation)
- Gradient 크기가 변함에 따라서 Adapted하게 learning rate을 바꾸는것과 이전의 gradient에 해당하는 momentum정보를 합쳐서 사용
- Parameter
- B1 momentum을 얼마나 유지시킬지
- B2 gradient squared에 대한 EMA정보
- 에타 라는 learningrate
- 입실론
- Regularization
- generalization을 잘되게 하려고 학습에 반대되는 규제를 건다
- Early Stopping
- generalize가 줄어드는 시점에서 멈춘다.

- Parameter Norm Penalty
- 파라미터가 너무 커지지 않게 한다
- Data Augmentation
- 데이터가 많이 없을 때 레이블이 변하지 않는 조건내에서 데이터를 내가 지지고 볶아서 데이터를 만든다


- Noise Robustness
- data augmentation과 유사하지만 noise를 입력에다만 넣는게아니라 웨이트에다가도 집어넣는다

- Label Smoothing

- Dropout
- neural network의 레이어마다 일정 개수의 w를 0으로 바꿔줌
- 각각의 뉴럴들이 robust한 피쳐를 잡을 수 있다

- Batch Normalization
- 간단한 분류에서 사용해도 좋다
반응형
'부스트캠프 AI Tech 2기 > 2기 U-Stage' 카테고리의 다른 글
| 2주차 조금..? Modern Convolution Neural Network (0) | 2021.08.12 |
|---|---|
| 2주차 Convolution (0) | 2021.08.12 |
| 2주차 MLP (Multi-Layer Perceptron) (0) | 2021.08.09 |
| 2주차 딥러닝에서 사용되는 용어 (0) | 2021.08.09 |
| 1주차 MLE(최대우도법) (0) | 2021.08.09 |