
한타입의 데이터가 아니라 다른 특성을 가진 데이터 타입들을 같이 활용하는 학습법
ex) 텍스트, 사운드같은 데이터를 함께 사용
서로 다른 데이터타입, 자료구조를 사용
1. Overview of multi-modal learning

- unimodal: 단일 도메인을 사용
- multimodal: 두개이상의 도메인을 사용
1) Challenge - Different representations between modalities
- 오디오는 waveform
- image는 3d array
- text는 word의 임베딩벡터
2) Challenge - 서로다른 modality에서 오는 정보의 양의 unbalance하고 feature space도 unbalance하다

3) Challenge - training이 잘 안돼서 neural network가 쉬운 데이터에 대해서 obvious하게 학습된다.
- 까다로운 데이터는 안쓰고 하나의 모달에 바이어스하게된다.
- 예를들어 영상을 보고 무슨 상황인지 알고싶은데 소리를 지르는 상황과, 노래를 부르는상황에 대한 구분을 오디오로 해야하지만 사운드를 참조하는 경우가 많이 없어서 neural network가 visual data만 보는게 더 성능이 좋다고 느껴지면 visual에 bias된다

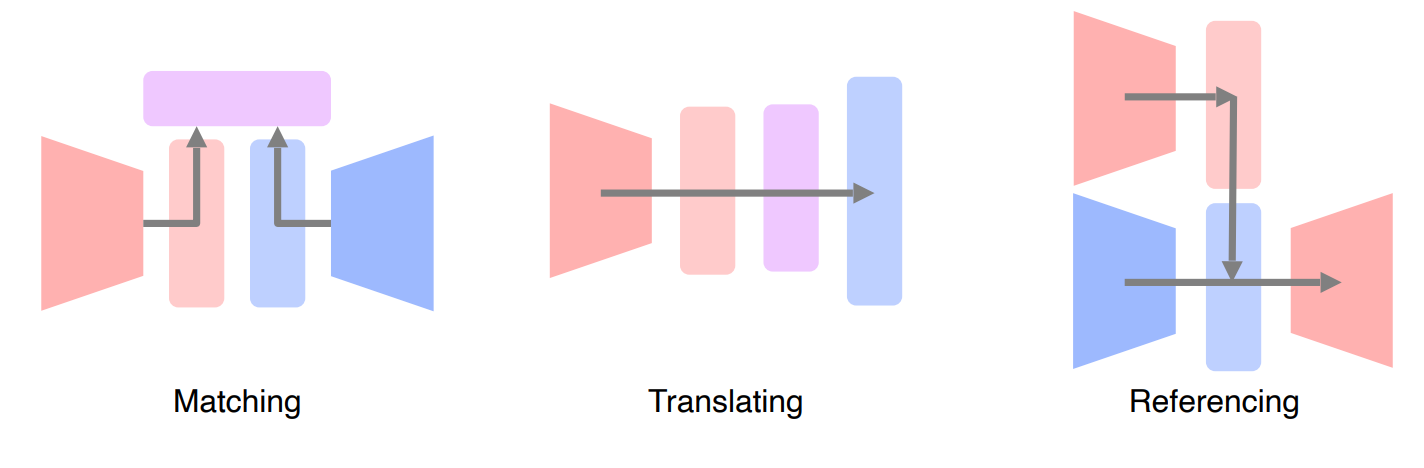
이런 문제를 어떻게 해결할까?
- Matching: 두개의 다른 데이터 타입을 공통된 space로 보내서 matching하여 사용
- Translating: 하나의 Modality를 다른 Modality로 Translation해서 사용
- Referencing: 하나의 Modality에서 결과를 도출해낼때 다른 Modality를 참조해서 결과를 도출
2. Multi-modal task(1) - Visual data & Text
2-1 Text Embedding
- 일반화가 가능하고, 유사한 단어끼리는 근접하다.
- ex) man과 woman사이의 거리는 king과 queen 사이의 거리와 동일하다

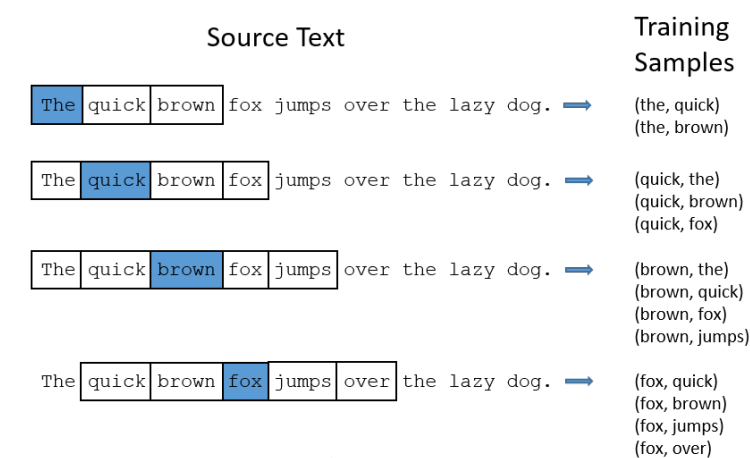
1) word2vec - skip gram model

- W와 W'을 학습한다
- W에서 하나의 row들이 하나의 wordembedding vector가된다
- Vdim은 onehotencoding되어있다
- input으로 V-dim에서 한개의 단어가 들어오면 N dim을 거쳐 y1j 에서 N-dim은 현재 단어의 이전에 어떤 단어가 나와야하는지, 그y2j는 그다음에 어떤단어 yCj위치에는 또 어떤단어가 나와야되는지를 체크하여 데이터 패턴을 학습
학습 테스크
- N개의 word를 prediction하는 테스크로 학습
- 하나의 word에 대해 주변 word간의 관계를 학습
-ex) brown이 주어지면 첫번째는 brown이 들어오면 the가 나와야된다 등
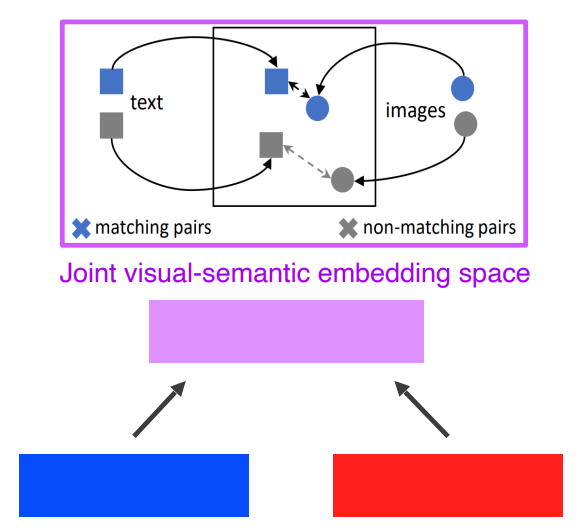
2-2 Joint Embedding (Matching)
matching을 하기위한 공통된 embedding vector를 학습하는 방법
예시1) Image Tagging
Image에서 Tag로 Tag에서 Image로

d라는 같은 차원으로 보내서 호환성을 고려한다

매칭되는 image와 tag사이의 거리는 줄이고, 그렇지 않은 아이템의 거리는 패널티를 줘서 더 멀리 떨어지게한다
이렇게 push와 pull을 하는 방법을 matric learning이라고 한다
예시2) 이미지 to 레시피, 레시피 to 이미지
텍스트에 대해서는 ingredients를 확인하는 RNN과 instructuions를 확인하는 RNN을 학습해서 fixed dimension을 만들고, 이미지는 CNN을 통해 학습한다
이렇게 나온 결과들을 하나의 dimension으로 보내서 cosine simillarity와 semantic regularization loss를 사용한다
2-3 Cross modal translation ( Translating )
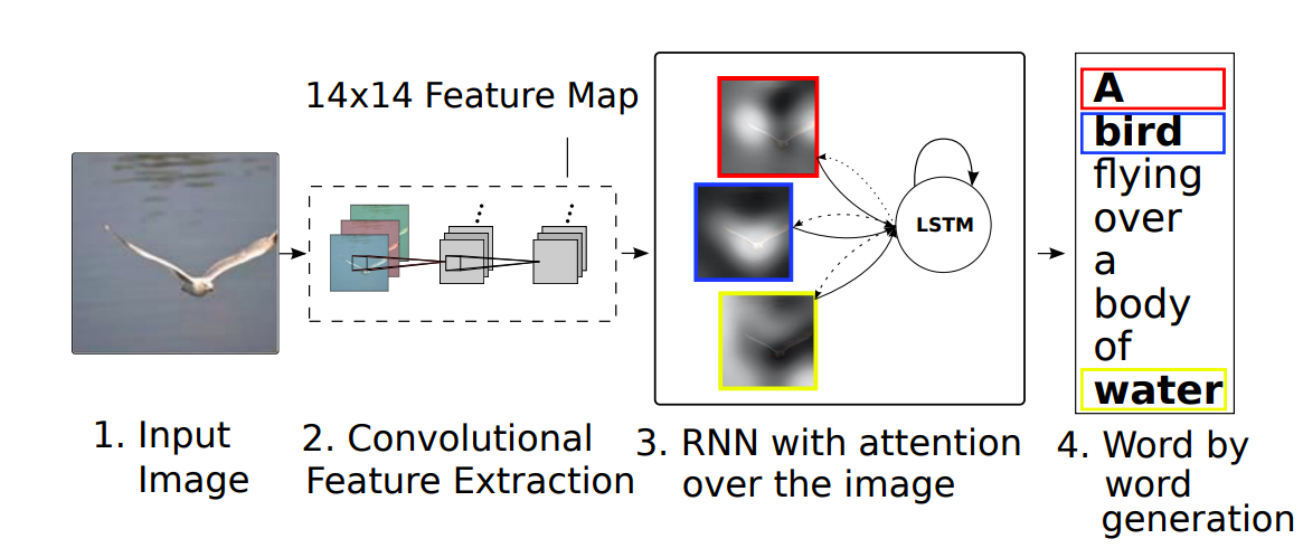
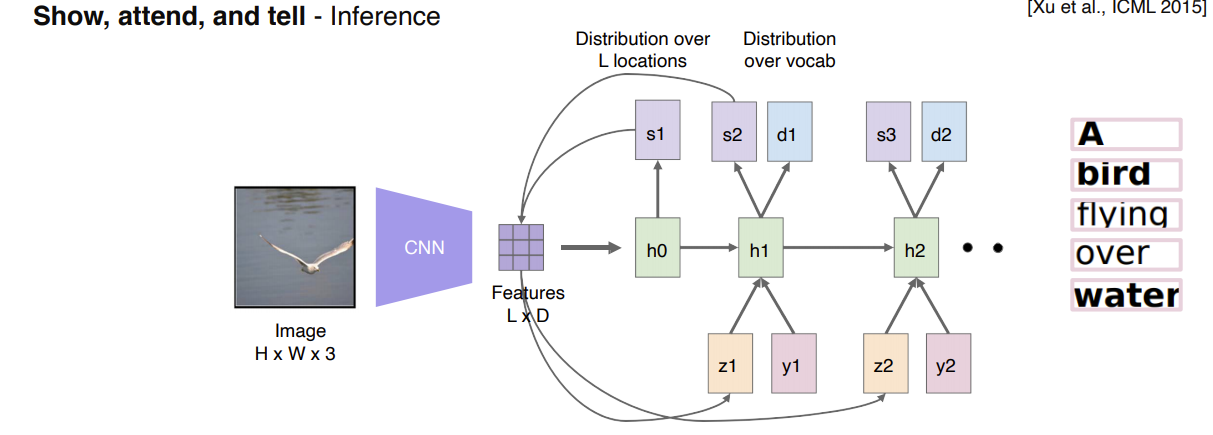
예시1) Image Captioning
이미지가 주어지면 이미지를 가장 잘 설명하는 text description 즉 Image to Sentence
이미지는 CNN 텍스트는 RNN을 사용하는게 좋다

Show attend and tell 이라는 방법으로 CNN과 RNN을 합쳤음
각 단어가 나올때 그 단어에 해당하는 이미지의 위치를 더 attension하게 함

- Soft Attention Embedding
사람이 얼굴을 쳐다볼때 우측의 그림처럼 사람의 특징을 하나하나 살펴보고 그 후에 얼굴의외곽을 살펴본다
feature가 들어오면 RNN을 거쳐서 어디를 reference를 해야하는지 잘 보고 heatmap으로 만든다
heatmap과 feature를 결합하여 Z라는 벡터를만든다.
Z는 inner product로 만든다.

점진적으로 내가 봐야하는 이미지 부분을 한칸씩 보면서 z를 생성하고 생성된 z와 이전 단어를 고려하여 다음번에 볼 이미지를 확인하고, word를 생성한다.
- Text to Generative model
- Generator: 텍스트 전체를 fixed dimension벡터로만들고 앞에 가우시안 랜덤코드를 붙여준다 ( 항상 똑같은 input이 들어갔을때 다양하게 나오게끔 해준다 ) 즉 Conditional GAN
- Discriminator: 해당 문장에서 사용한 sentence정보를 같이줘서 setnence condition 하에 입력된 영상이 true냐 false냐를 검사
2-4 Cross modal reasoning (Referencing)
- Visual question answering
Image Stream과 Question Stream이 존재
두개 다 각각의 fixed dimension을 출력
두개의 feature가 interaction할 수 있게 point-wise multiplication한다
이는 하나의 joint embedding이라고도 할 수 있다

3. Multi-modal task(2) - Visual data & Audio
sound는 시간축에 대하여 waveform으로 1dimension으로 표현된다
뉴럴네트워크에선 Acoustic feature, 스펙토그램이나 mfcc의 형태로 변환하여 사용
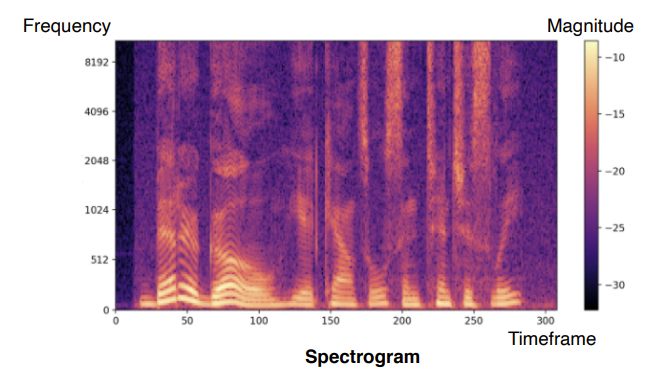
3-1 Sound representation
- Short time Fourier transform(STFT)
시간축 t에대하여 있는 waveform에 대하여 fourier transform을 적용하면 주파수 축으로 옮기게 되는데 시간에 따른 변화를 파악할 수 없다.
그래서 A라는 짧은 구간에 대해서만 Fourier transform을 시행

Spectogram
시간에따른 주파수를 보여줌
3-2 Joint Embedding (Matching)
scene recognition by sound
현재 들리는 사운드가 어디서 일어나는 사운드인지를 판별 ( 해변가, 클럽, 교실 등)
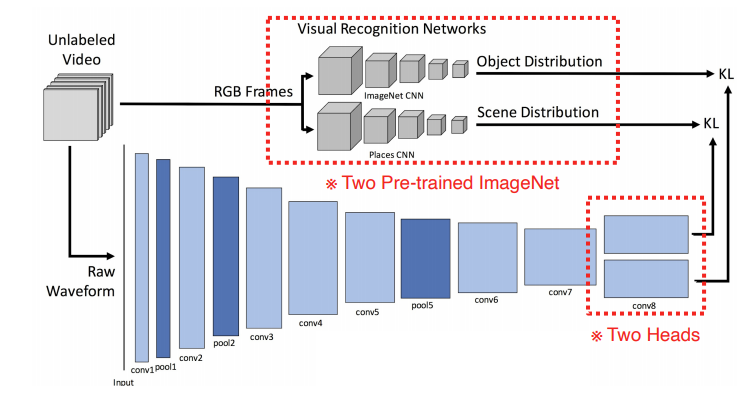
Sound Net
오디오에대한 학습법을 어떻게 할것인지를 제시한 논문
video만 잔뜩 주어진 데이터셋을 갖고 기존의 pre-trained되어있던 네트워크를 fixed하여 사용한다
첫번째 CNN에서는 Object detection, 두번째 CNN은 어떤 장면에서 촬영되고있는지에 대한 판별
video의 음성데이터를 Raw_waveform형태로 추출하여 CNN구조에 넣어준다.
1D CNN이고, 맨 마지막에서는 2개의 HEAD로 분리한다.
첫번째 HEAD는 scene distribution을 따라하여 place recognition을 할 수 있도록 하고
두번째 HEAD는 object recognition을 할 수 있도록 KL divergence를 minimize하게 학습한다
visual 쪽은 fixed되어있고 음성쪽만 학습한다.
이 논문에선 spectogram 대신 waveform을 사용하였는데 아마 spectogram에 대한 고려를 하지 않았던걸로 짐작
3-3 Cross modal translation (Translation)
Speech2Face
이미지의 얼굴과 sound가 이미 annotated되어있음
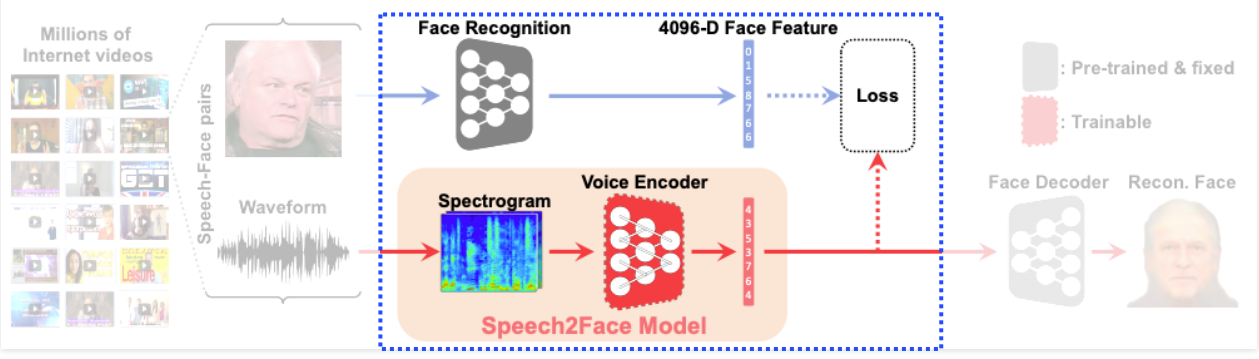
Image to Speech

3-4 Cross modal reasoning (Translation)
Sound source localization
- 소리가 주어지고 이미지가 주어지면 이 소리가 어디서 나는지 Attention하는 task
- 마이크 하나에서 소리가나오면 소리의 의미(context)와 매칭이되는 semantic한 vision network
- 최종적으로 localization을 체크하는게 task다

비디오에 보면 사운드와 영상은 항상 pair로 갖고다니기 때문에 annotation처럼 사용될 수 있다.
그래서 unsupervised로도 학습이가능하다
아래 영상처럼 speech를 따로 분리하는것도 가능하다.
https://www.youtube.com/watch?v=rVQVAPiJWKU
Lip Movements Generation - synthesizing Obama example
이런 재밌는 task도 있음
'부스트캠프 AI Tech 2기 > 2기 CV U-Stage' 카테고리의 다른 글
| 3D understanding (0) | 2021.09.18 |
|---|---|
| Image Captioning (0) | 2021.09.17 |
| Conditional GAN (0) | 2021.09.15 |
| Instance/Panoptic Segmentation and Landmark Localization (0) | 2021.09.14 |
| AutoGrad (0) | 2021.09.14 |