
Semantic Segmentation과 ObjectDetection보다 더 유용한 Instance Segmentation, Panoptic Segmentation이 더 유용함
1.Instance segmentation

1-1 Mask R-CNN
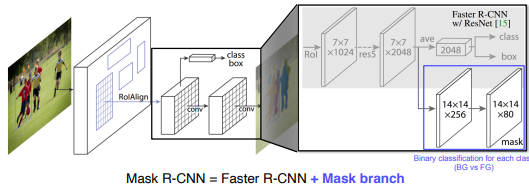
- RoIAlign을 사용
- Faster R-CNN + Mask branch
- 기존 Fast R-CNN과 유사한 class+box부분에서 class가 무엇인지를 나타내는 값을 바운딩 박스마다 mask branch의 14*14*80에게 전달해서 어떤클래스인지를 확인한다
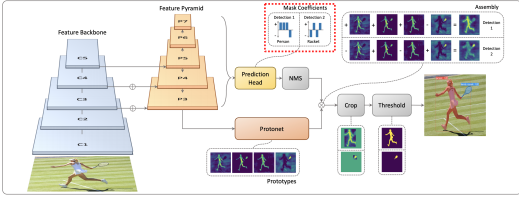
1-2 YOLACT(You Only Look At CoefficienTs)
- One-stage detect
- protonet은적당한 수로 생성하고, 합성될 수 있는 재료를 제공한다
- prediction head에서 각dectection에 대해서 protonet에서 나온 prototype을 잘 합성하기위한 계수들(coefficient)을 출력한다
- 위의 결과를 protonet과 선형결합하여 각 딕텍션에 적합한 mask response map을 생성해준다
- detection_1 -> person
- detection_2 -> racket
YOLOACT_EDGE
- YOLOACT가 좋더라도 아직 작은 디바이스에 올리기는 쉽지않음
- 그래서 이런 연구가 실행됨
- feature pyramid에서 이전에 연산한결과를 이후에 다시연산하지않고 값을 그대로전달함
- segmentation이 스무스하지 못하고 깜빡이는 현상이발생

2.Panoptic segmentation

2-1 UPSNet
- FPN구조 사용

- 물체와 배경을 인식하는 마스크도 존재
- instance head부분의 값을 원본이미지의 어디에 위치시킬지를 학습시키고 이를 보강하기위해 물체에 해당하는 부분을 더해줘서 학습
- insatnce로 사용된 부분들을 제외한 나머지 부분을 1channel로 더해준다
- 배경을 나타내는 마스크는 최종출력 (노란색)으로 이동

2-2 VPSNet (for video)
- 두 시간차이를 가지는영상 사이에 파이라는 모션맵을 사용해서 각 프레임에서 나온 피쳐맵을 모션에 따라 wrapping해준다
- 모션맵이라는것은 두개의 영상이 있으면 한 영상에서 하나의 포인트가 다음영상으로 어디로 가는지 대응점들을 모든픽셀에 대해 가지고있음
- 원래 각 프레임 t에서 찍혔던 feature와 wrapping된 feature를 사용
- 현재 프레임에서 가려져서 안보이거나 놓친부분을 이전 프레임에서 가져온 데이터를 활용해서 추적
- 기존의 roi feature와 이전의 roi feature 연관이 어떻게 되어있는지, 이전에 몇번id를 가졌던 물체였던지를 체크
- 이전에서 없던 id는 새로 id를 부여하여 tracking
- 위의 결과들로 Bounding box, Mask head, Semantic Head에서 나온 결과들을 하나의 panotic segmentation map으로 활용
3.Landmark localization
- 얼굴의 keypoint나 모션의 keypoint등에서 사용
- 중요하다고 생각하는 keypoint, landmark라고 부르는 부분들을 정의하고 추적하는 것
3-1 coordinate regression vs heatmap classification
- coordinate regression: 다소 부적확하고 일반화의문제
- heatmap classification: 정확도는 좋으나 연산작용이 많이필요, 각 채널이 하나의 class를 보고있을때 keypoint가 발생할 확률맵을 각 픽셀별로 classification
heatmap표현은 각 위치마다 confidence가 나오는 형식
- size: 미리 임의의크기를 정함, 출력해상도의 크기
- x,y: 사이즈에 대한 배열을 미리 생성
- x0,y0(xc,yc): center point에 대응하도록 만든다 (가운데 위치한값)
- x+y를 하면 <1xN + Nx1> Broad Casting이 일어나서 NxN 사이즈의 값이나옴

3-2 Hourglass Network
- Unet과 비슷
- skip connection을 이용하는데 이때 1개의 conv를 거쳐서 전달함

3-3 DensePose

- UV map 표현을 사용
- UVmap은 표준 3D모델의 각 부위를 2D로 펼쳐서 이미지 형태로 만들어 놓은 표기법
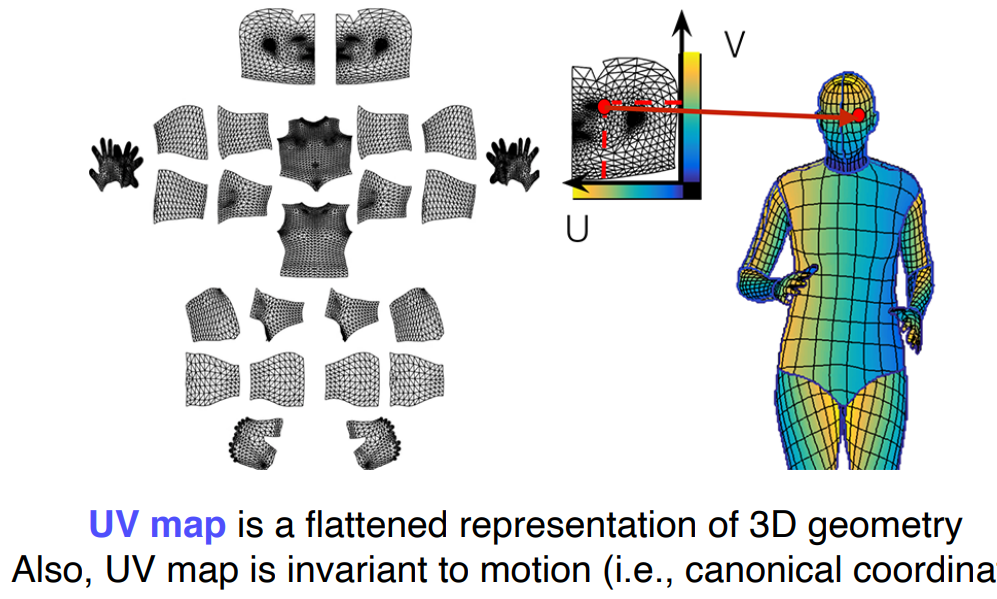
마스크브랜치가 UVmap으로 변환

- Faster R-Cnn과 UVmap을 사용함
3-4 RetinaFace
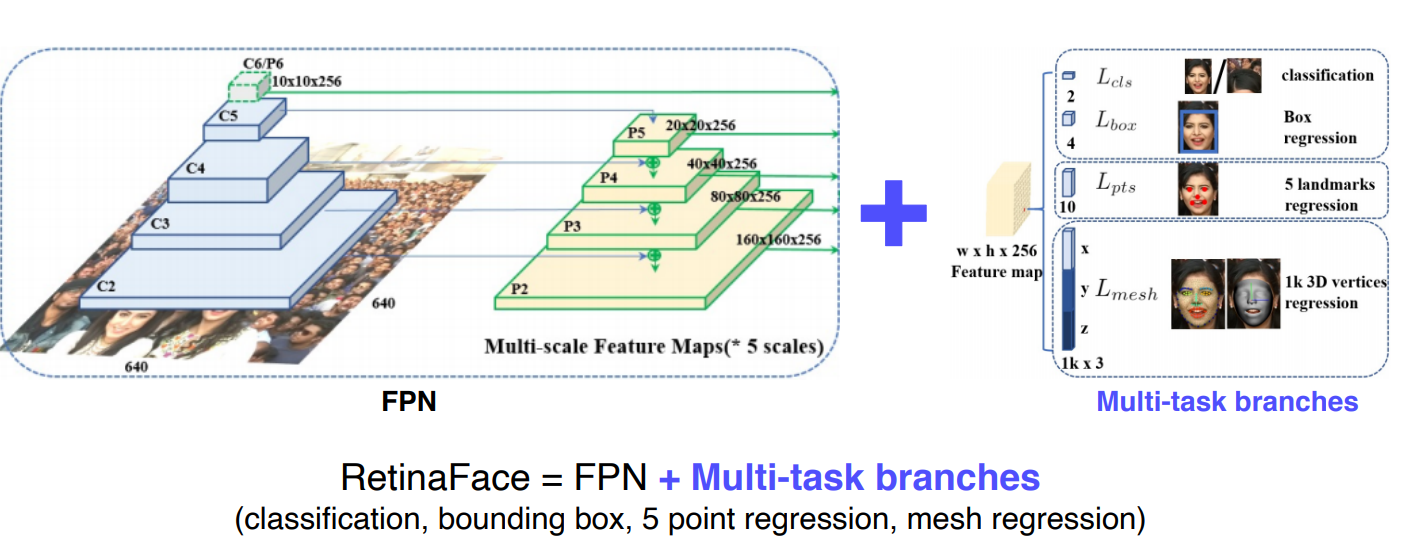
- FPN과 Multi task branches를 사용
- 다양한 테스크 분류를 사용하여 다양한 테스크를 한번에 풀도록 사용
- Multitask는 공통적으로 얼굴에대한 다른 task에서 오는 공통된정보에서 backbone network가 강하게 학습됨
- 1개의 backbone을 업데이트할 때 5개의 multitask를 고려하여 업데이트됨
- 적은 데이터로도 강한 학습효과를 기대할 수 있다
backbone network위에 원하는 target task에 해당하는 head만 만들어주면 다양한 응용이 가능
-> CV의 큰 디자인패턴중 하나
4.Detecting objects as keypoints
4-1 CornerNet
- 왼쪽위와 오른쪽아래의 코너에 점을 받아서 detection한다
- single stage구조로 성능보다는 속도에 초점을 맞춤
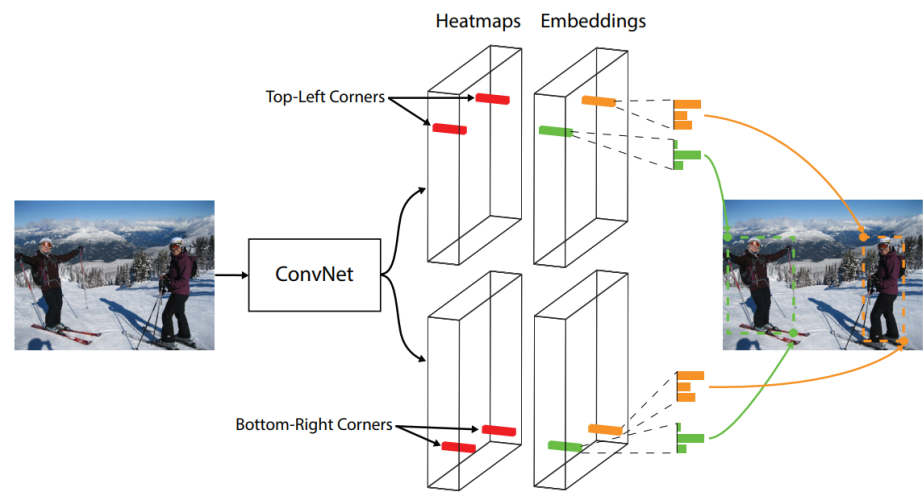
4-2 CenterNet-1
- 위의 코너뿐 아니라 가운데도 중요한 점이라고 생각해서 Top Left, Center, Bottom Right 세 점을이용
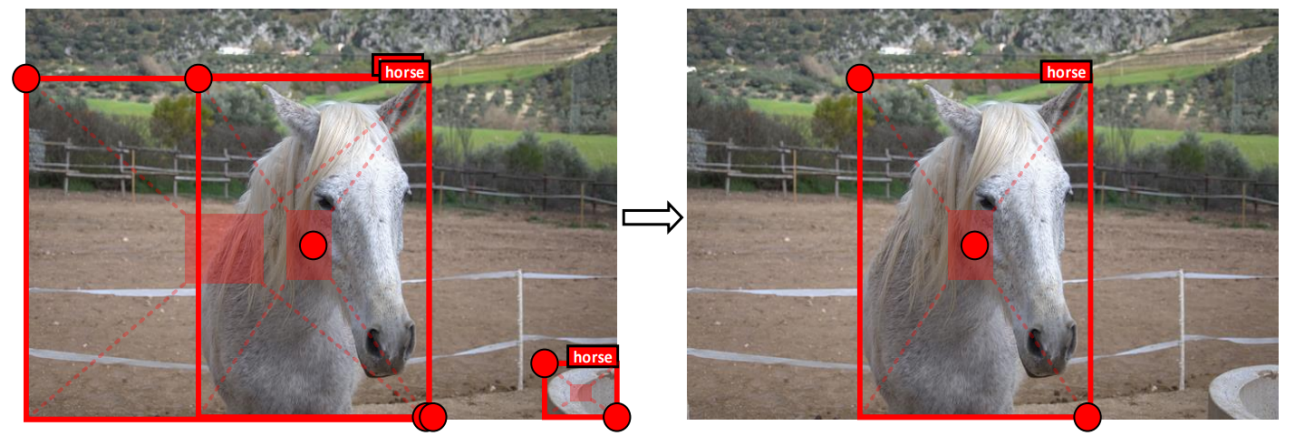
4-3 CenterNet-2
두번째 실험으로는 Width, Height, Center 세 점을 이용한다
Center에 좀더 초점을 맞추려면 topLeft와 bottomRight가 아닌 center기준으로 width와 height가 더 정확하다고 판단했기 때문이다
'부스트캠프 AI Tech 2기 > 2기 CV U-Stage' 카테고리의 다른 글
| Multi Modal Learning (0) | 2021.09.17 |
|---|---|
| Conditional GAN (0) | 2021.09.15 |
| AutoGrad (0) | 2021.09.14 |
| CNN Visualization (0) | 2021.09.13 |
| Object Detection (0) | 2021.09.10 |