
기존의 Generative Model은 랜덤하게 샘플링해서 생성 할수는 있었지만, 조작할 수는 없었다.
생성이 더 유용하게 쓰이려면 유저의 의도를 반영할 수 있어야 하는데 이런 방식을 Conditional Gan이라한다.
1. Conditional Generative Model

1-1 CGAN의 응용 사례
- vision task외에도 low quality의 audio를 high quality의 audio로 변환해주는 GAN
- 중국어를 영어로 번역해주는 GAN
- Title과 Subtitle만 주고 Article을 만들어내는 GAN
GAN

1-2 CGAN
- GAN과 거의 유사하지만 c라는 input이 추가됨 (입력이 달라짐)

- Image-to-Image translation을 통해 Style transfer, Super resolution, Colorization
1-3 Super Resolution GAN
- 입력은 저해상도 영상 출력은 고해상도 영상
구조
- 왼쪽은 GAN을 사용하기 이전에 Generative 모델만을 이용해서 MAE 혹은 MSE를 사용한 regression model 사용
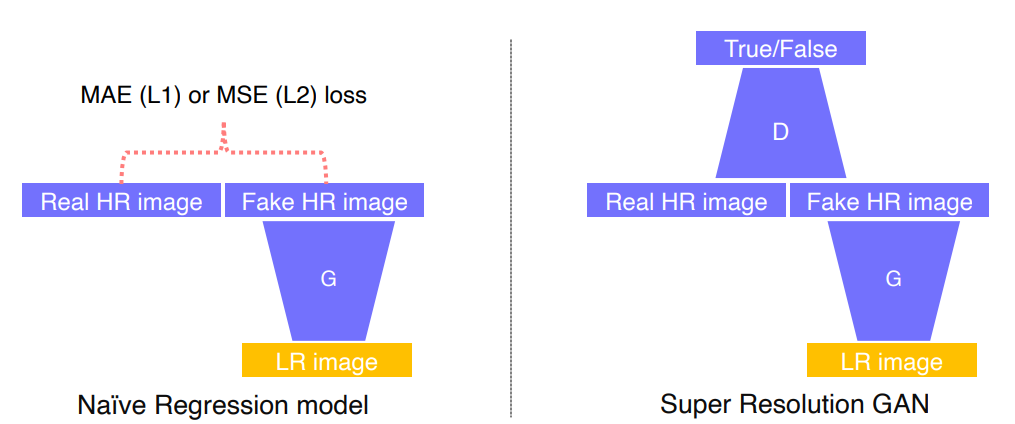
- 픽셀 자체에 intensity차이를 측정한다.
- 평균 에러를 구하다보니까 출력결과와 비슷한 에러를 가지는 많은 패치들이 존재해서 구분성이 떨어진다
- 아래의 그림처럼 MAE나 MSE를 사용해서 찾아낸 Manifold가 존재한다면 내가 생성한 패치가 반대쪽이랑은 에러가 엄청 크기때문에, 에러를 계속 개선해나간다면 어정쩡한 이미지가 나오게 될거다

- 만약 Colorize하는 task가 존재하고, 이미지의 컬러가 white와 black만 있다면 L1 loss를 사용해서 구하면 white와 black의 중간인 애매한 gray color를 output으로 사용하게된다
- GAN loss(Discriminator)를 사용하게되면 gray가 들어오면 '난 real data중에 너같은색은 본적이없어'라고 하면서 real data라고 판별하지 않음.
- black 또는 white를 맞추기에 정확한 특성을 갖고있다.

- MAE loss를 사용하는 것보다 GAN을 사용한게 더 sharp하고 선명하다는것을 알 수 있다.

2. Image translation GANs
2-1 Pix2Pix
- Pairwise data가 필요한 Supervised Learning이다

- L1_loss를 사용해서 좀더 reallity한 loss를 만든다
- GAN Loss만을 사용하게 되면 얼마나 다른지를 알려주지 않고 real이냐 fake냐 만 알려주기때문에 그에대한 어느정도 가이드를 L1_loss를 통해 제공
- y와 비슷한영상이 나오는데 GAN을 이용해서 좀더 reallity하게 만들어라 라고 제약을 걸어줌
- GAN의 학습이 불안정하고 어려웠던 시절 L1_loss를 사용한 학습의 보조 역할
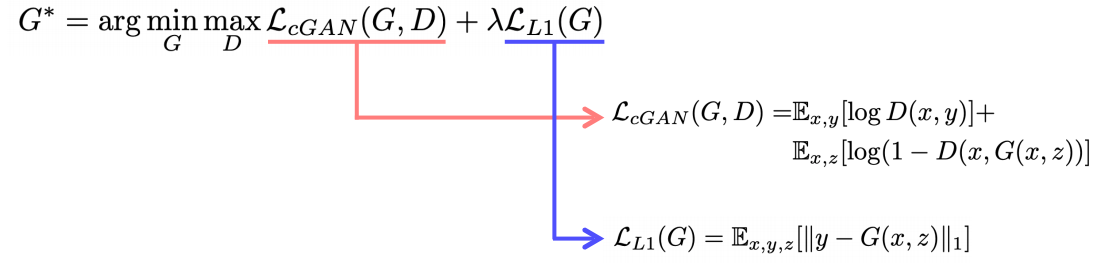
- L1만 사용하게되면 제대로 sharp한게 나오지 않게된다.
- 우측 colorization에서 L1+cGAN 여우사진은 잘 되지않았지만 다른건 더 잘됨

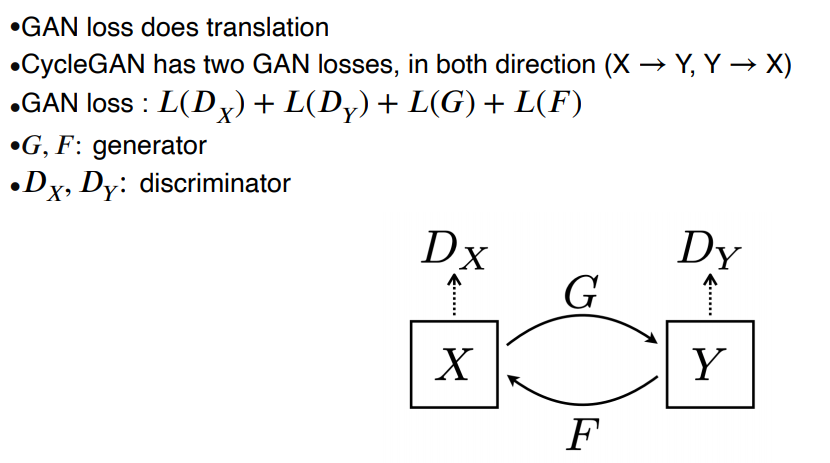
2-2 CycleGAN
- Paired data를 얻기 어렵기 때문에 연구됨
- 도메인간의 non-pairwise dataset만으로 학습이 가능하다
Loss Function of CycleGAN
CycleGANloss = GAN loss + Cycle_consistency loss
- GAN loss: X에서 Y로 Y에서 X로 가는 loss를 계산
- Cycle-consistency loss: 이미지가 translation된 결과를 갖고 다시 돌아왔을때 원본이미지와 동일해야한다.

1) GANloss (Adversarial loss)
- GANloss만 사용하면 Mode collapse라는 문제가 생겨서 항상 같은 output만 생성하게되는 문제가 발생하는데 왜냐하면 Discriminator는 output을보고 realistic하다고만 판단하기때문이다.
- 이 이후에는 G는 더이상 학습하지 않는다. 그래서 X스타일이 항상 잘 맞는다고 생각해서 F는 만족하고 멈춘다.
- 최적화의 localminima와 유사

2) cycle consistency loss
- 위의 문제를 해결하기위해 나왔음
- 스타일만 보는게아니라 contents도 유지가 돼야한다는 것을 강조하기 위해 나온 loss
- X에서 Y로가고 Y에서 다시 X로 변환하는데 차이가 있으면 안된다 (원본 유지)
- 그렇기때문에 No supervised learning (self-supervision)
X라는 스타일의 데이터셋과 Y라는 스타일의 데이터셋만 주어지면 이 두개사이의 translation 관계를 학습할 수 있는 방법
2-3 Perceptual Loss
- high quality의 output을 만들기 위한 방법
1) GAN loss
- training하기 어렵다
- 하지만 pre-trained network가 필요하지않다
- 그렇기 때문에 제약사항없이 데이터만 있으면 어떤 task도 가능
2) Perceptual loss
- training하기 편하다
- pre-trained network를 사용해야한다
- pre-trained된 network의 첫번째 레이어를보면 edge를 찾는 filter, 방향성을 파악하는 filter, color의 difference를 체크하는 filter등이 존재한다
- 이는 사람의 시각과 유사한 역할을 한다
- 중요한부분과 상대적으로 신경쓰지 않는것을 구분해서 연관을 지을 수 있을지 않을까? 라는 의문점에서 시작
순서
- Image Transform Net: 이미지를 트랜스폼해주는 네트워크
- y hat은 transform된 (생성된) 아웃풋
- Loss Network은 VGG16의 imageclassification에 사용된 weight를 사용한다. training시 fix해서 업데이트하지 않는다
- 이 네트워크로 feature를 뽑는다
- 각 network의 activation에 yhat을 주입한다.
- style target과 content target을 이용해서 loss를 measure한다
- y hat에 backpropagation을 해서 Image Transform Net을 업데이트한다.

2-1) Feature reconstruction loss (Content target)
- content target에 변환되기 전의 이미지X를 vgg에 넣어주고 feature를 추출한다
- Transformed Image도 vgg에 넣어주고 feature를 추출한다
- 위의 두개의 feature에대한 L2 loss를 연산 하여 Y를 업데이트한다

2-2) Style reconstruction loss
- 우리가 변환하고 싶어하는 style을 target으로 넣어준다
- 위의 과정과 동일하게 transformed Image를 vgg에 넣어준것으로 나온 feature와 style target을 사용해서 vgg에 넣어준것으로 나온 feature를 추출한다
- style이라는 것을 담기 위해서 Gram matrics라는것을 사용한다.
* Gram matrics: 일반적으로 feature map에 담긴 통계적인 특징을 담도록 사용
- 하나의 conv에서만 grammatrics를 뽑고 loss 를 measure하는게 아니라 중간중간에 채널들을 다 뽑아서 여러곳의 서로 다른 레벨에서 실행하고 grammatrics
- style간의 correlation의 정보를 grammatrics에 저장하게 되고 Transformed Image를 만드는 함수는 gram matrics를 따르도록 학습이된다

3. Various GAN applications
3-1 Deepfake
- 많은 윤리적인 문제가 발생할 수 있다

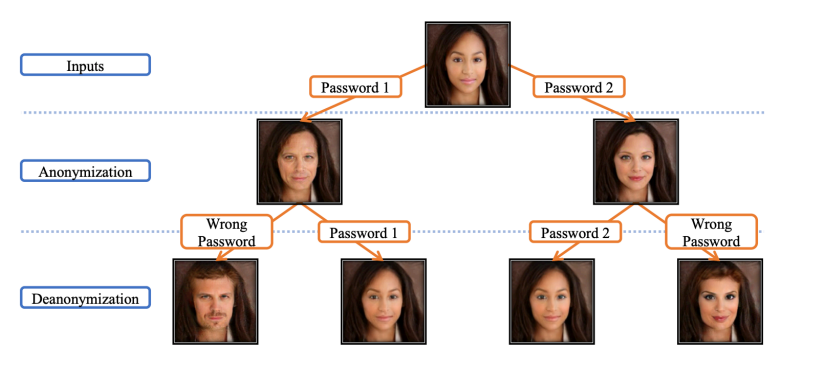
3-2 Face anonymization with passcode
3-3 Video translation (manipulation)

'부스트캠프 AI Tech 2기 > 2기 CV U-Stage' 카테고리의 다른 글
| Image Captioning (0) | 2021.09.17 |
|---|---|
| Multi Modal Learning (0) | 2021.09.17 |
| Instance/Panoptic Segmentation and Landmark Localization (0) | 2021.09.14 |
| AutoGrad (0) | 2021.09.14 |
| CNN Visualization (0) | 2021.09.13 |