
반응형
AutoGrad(Automatic Gradient)
automatic differentiation을 활용한 딥러닝 라이브러리
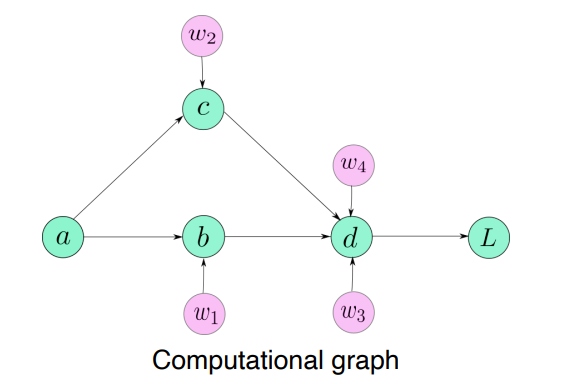
backward를 쉽게 구현하기 위한 Computational graph를 통해 어떻게 연산되었는지 history를 다 가지고있다.
- requires_grad
- 해당 변수에 gradient를 저장할 수 있게끔 만든다.
- 그래서 x.grad를 호출할 수 있다.
x = torch.randn(2, requires_grad=False)
y = x * 3
gradients = torch.tensor(\[100, 0.1\], dtype=torch.float)
y.backward(gradients)
print(x.grad)
->> 에러
이유: requires\_grad = False로 지정하면 backward를 할 수 없다.computational graph를 가지고 있기 때문에 grad_fn에 어떤 연산이 수행됐는지 저장됨
x = torch.randn(2, requires_grad=True)
y = x*3
z = x/2
w = x+y
x,y,z,w
---->
(tensor([-0.3570, -0.5410], requires_grad=True),
tensor([-1.0710, -1.6229], grad_fn=<MulBackward0>),
tensor([-0.1785, -0.2705], grad_fn=<DivBackward0>),
tensor([-1.4280, -2.1638], grad_fn=<AddBackward0>))- retain_graph = True
- retain_graph를 True로 하지 않으면 에러가 난다.
- backward 내부의 computational graph가 항상 저장되어있지 않고 지운다.
- retain_graph를 True로 하면 그래프가 날라가지 않고 유지된다.
- backward를 두번하면 이전 결과가 지워지지않고 accumulated 된다.
- optimizer zerograd를 하지 않으면 gradient가 계속 accumulate된다.
gradients = torch.tensor(\[100, 0.1\], dtype=torch.float)
y.backward(gradients, reatain\_graph = True)
print(x.grad)
y.backward(gradients)
print(x.grad)
[300, 0.3]
[600, 0.6] Hook
- create simple layer
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.conv1 = nn.Conv2d(1,10,5)
self.pool1 = nn.MaxPool2d(2,2)
self.conv2 = nn.Conv2d(10,20,5)
self.pool2 = nn.MaxPool2d(2,2)
self.fc = nn.Linear(320,50)
self.out = nn.Linear(50,10)
def forward(self, input):
x = self.pool1(F.relu(self.conv1(input)))
x = self.pool2(F.relu(self.conv2(x)))
x = x.view(x.size(0),-1)
x = F.relu(self.fc(x))
x = F.relu(self.out(x))
return x
def hook_func(self, input, output):
print('Inside' + self.__class__.__name__+'forward')
print('')
print('input: ', type(input))
print('input[0]: ', type(input[0]))
print('output: ', type(output))
print('')
net = SimpleNet()
# forward hook에 내가 정의한 hook_func를 등록한다
net.conv1.register_forward_hook(hook_func)
net.conv2.register_forward_hook(hook_func)
input = torch.randn(1,1,28,28)
out = net(input)
------->
InsideConv2dforward
input: <class 'tuple'>
input[0]: <class 'torch.Tensor'>
output: <class 'torch.Tensor'>
InsideConv2dforward
input: <class 'tuple'>
input[0]: <class 'torch.Tensor'>
output: <class 'torch.Tensor'>
이외에도
- register_forward_pre_hook: forward path를 하기 바로 전 실행
- register_backward_hook: 에러 계산하고 backward함수 실행하고 gradient를 받은 후 실행
def hook_grad(self, grad_input, grad_output):
~~~~
~~~~
~~~~
#선택적으로 return
return torch.Tensor(output*2)
# handler에 return값을 저장해서 갖고있다가 event를 제거해줄 수 있다
h = net.conv1.register_forward_hook(hook_func)
h.remove()중간의 activation값을 저장하고 싶다면 전역변수를 선언해서 사용
save_feat = []
def hook_feat(module, input, output):
save_feat.append(output)
return output
for name,module in model.get_module_shortcuts():
if(name=='target_layer_name'):
module.register_forward_hook(hook_feat)
img = img.unsqueeze(0)
s = model(img)[0]반응형
'부스트캠프 AI Tech 2기 > 2기 CV U-Stage' 카테고리의 다른 글
| Conditional GAN (0) | 2021.09.15 |
|---|---|
| Instance/Panoptic Segmentation and Landmark Localization (0) | 2021.09.14 |
| CNN Visualization (0) | 2021.09.13 |
| Object Detection (0) | 2021.09.10 |
| Semantic Segmentation (0) | 2021.09.09 |
반응형
AutoGrad(Automatic Gradient)
automatic differentiation을 활용한 딥러닝 라이브러리
backward를 쉽게 구현하기 위한 Computational graph를 통해 어떻게 연산되었는지 history를 다 가지고있다.
- requires_grad
- 해당 변수에 gradient를 저장할 수 있게끔 만든다.
- 그래서 x.grad를 호출할 수 있다.
x = torch.randn(2, requires_grad=False)
y = x * 3
gradients = torch.tensor(\[100, 0.1\], dtype=torch.float)
y.backward(gradients)
print(x.grad)
->> 에러
이유: requires\_grad = False로 지정하면 backward를 할 수 없다.computational graph를 가지고 있기 때문에 grad_fn에 어떤 연산이 수행됐는지 저장됨
x = torch.randn(2, requires_grad=True)
y = x*3
z = x/2
w = x+y
x,y,z,w
---->
(tensor([-0.3570, -0.5410], requires_grad=True),
tensor([-1.0710, -1.6229], grad_fn=<MulBackward0>),
tensor([-0.1785, -0.2705], grad_fn=<DivBackward0>),
tensor([-1.4280, -2.1638], grad_fn=<AddBackward0>))- retain_graph = True
- retain_graph를 True로 하지 않으면 에러가 난다.
- backward 내부의 computational graph가 항상 저장되어있지 않고 지운다.
- retain_graph를 True로 하면 그래프가 날라가지 않고 유지된다.
- backward를 두번하면 이전 결과가 지워지지않고 accumulated 된다.
- optimizer zerograd를 하지 않으면 gradient가 계속 accumulate된다.
gradients = torch.tensor(\[100, 0.1\], dtype=torch.float)
y.backward(gradients, reatain\_graph = True)
print(x.grad)
y.backward(gradients)
print(x.grad)
[300, 0.3]
[600, 0.6] Hook
- create simple layer
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.conv1 = nn.Conv2d(1,10,5)
self.pool1 = nn.MaxPool2d(2,2)
self.conv2 = nn.Conv2d(10,20,5)
self.pool2 = nn.MaxPool2d(2,2)
self.fc = nn.Linear(320,50)
self.out = nn.Linear(50,10)
def forward(self, input):
x = self.pool1(F.relu(self.conv1(input)))
x = self.pool2(F.relu(self.conv2(x)))
x = x.view(x.size(0),-1)
x = F.relu(self.fc(x))
x = F.relu(self.out(x))
return x
def hook_func(self, input, output):
print('Inside' + self.__class__.__name__+'forward')
print('')
print('input: ', type(input))
print('input[0]: ', type(input[0]))
print('output: ', type(output))
print('')
net = SimpleNet()
# forward hook에 내가 정의한 hook_func를 등록한다
net.conv1.register_forward_hook(hook_func)
net.conv2.register_forward_hook(hook_func)
input = torch.randn(1,1,28,28)
out = net(input)
------->
InsideConv2dforward
input: <class 'tuple'>
input[0]: <class 'torch.Tensor'>
output: <class 'torch.Tensor'>
InsideConv2dforward
input: <class 'tuple'>
input[0]: <class 'torch.Tensor'>
output: <class 'torch.Tensor'>
이외에도
- register_forward_pre_hook: forward path를 하기 바로 전 실행
- register_backward_hook: 에러 계산하고 backward함수 실행하고 gradient를 받은 후 실행
def hook_grad(self, grad_input, grad_output):
~~~~
~~~~
~~~~
#선택적으로 return
return torch.Tensor(output*2)
# handler에 return값을 저장해서 갖고있다가 event를 제거해줄 수 있다
h = net.conv1.register_forward_hook(hook_func)
h.remove()중간의 activation값을 저장하고 싶다면 전역변수를 선언해서 사용
save_feat = []
def hook_feat(module, input, output):
save_feat.append(output)
return output
for name,module in model.get_module_shortcuts():
if(name=='target_layer_name'):
module.register_forward_hook(hook_feat)
img = img.unsqueeze(0)
s = model(img)[0]반응형
'부스트캠프 AI Tech 2기 > 2기 CV U-Stage' 카테고리의 다른 글
| Conditional GAN (0) | 2021.09.15 |
|---|---|
| Instance/Panoptic Segmentation and Landmark Localization (0) | 2021.09.14 |
| CNN Visualization (0) | 2021.09.13 |
| Object Detection (0) | 2021.09.10 |
| Semantic Segmentation (0) | 2021.09.09 |