
1. EfficientUnet baseline
1.1 model불러오기
1) Segmentation Models라는 Library를 사용
- 많은 형태의 Encoder, Decoder Network를 제공
1.2 학습시키기
사용방법
- encoder name에 따라 encoder weights를 사용하지 못하는 것들도있다.

2. baseline 이후에 실험 해봐야할 사항들
2.1 주의해야할 사항들
1) 디버깅모드
- 샘플링을 통해서 데이터셋의 일부분만 추출하여 실험
- epoch를 1~2정도 설정하여 loss가 감소하는지 확인
2) 시드 고정
- torch 외 numpy, os 관련 시드 고정
- validation 검증셋의 시드 고정
3) 실험 기록
- Network 종류, Augmentation 방법, Hyperparameter 등 성능에 영향을 주는 조건을 바꿔가며 실험을 진행
- 노션, 구글 스프레드시트 등 사용
4) 실험은 한번에 하나씩
- 실험을 할 때에는 하나의 조건만을 변경해가며 실험
- Augmentation과 Network종류를 동시에 변경하면안됨
5) 팀원별 역할분배
• 하나의 베이스라인 코드를 기반으로 가장 좋은 솔루션을 만들기?
• 같은 코드에 실험을 서로 중복되지 않게 진행 !
• 독립적으로 베이스라인 코드를 만들어서 마지막에 앙상블?
• EDA / 코드 만들기 / 솔루션 조사 / 디스커션 조사 등 역할을 분배할 지?
-> 솔루션, 디스커션조사는 한사람이 해서 공유
각 모델에 맞는 optimizer가 존재할텐데 어떤 baseline코드에서는 효과적일텐데 다른곳에서는 효과적이 아닐 수 있다.
2.2 Validation
- 제출을 하지 않아도 모델의 성능을 평가할 수 있다.
- public 리더보드의 성능에 오버피팅 되지 않도록 도와준다
1) Hold Out
- 전체 데이터를 8:2로 분리해서 validation을 사용
- 빠른 속도로 모델 검증이 가능
- 20%의 valid data는 학습에 사용할 수 없음
2) k-fold
- train-valid를 동일하게 분리하지만 모든 데이터에 대해서 validation을 만든다
- ex) 5개로 나온 모델을 앙상블하여 결과를 예측한다
- 이렇게 사용되면 모든 training 데이터에 대해 고려했다고 볼 수 있다.
- 하지만 K배의 속도만큼 오래걸린다
3) Stratified K-fold
- 기존 fold는 class의 비율을 고려하지 않았지만 이 방법은 class를 균형있게 split한다

4) Group K-fold

2.3 Augmentation
- 데이터 수를 증가
- 일반성강화
- 성능향상
- class imbalance 해결
- Albumentation을 자주 사용함
- Augmentation은 도메인에 맞게끔 적용해야한다
ex) 아무때나 flip을 하면 안된다
1) Cutout

A.CoarseDropout( max_holes=8, min_holes=4, max_height=20, min_height=8, max_width=20, min_width=8, p=1.0)
- 위의 코드로 하더라도 원하는데로 잘 가려주지 않는다.
2) Gridmask
- 위의 이미지처럼 object를 제대로 가리지 않기 때문에 이를 해결해주기 위해 나온 기법
A.GridDropout(holes_number_x=4, holes_number_y=4, p=1.0)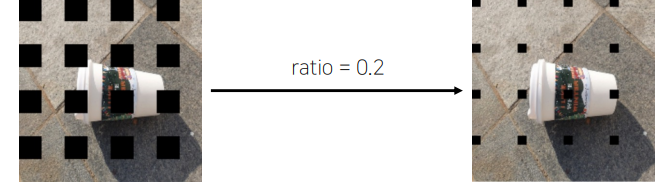
3) Mixup

4) Cutmix

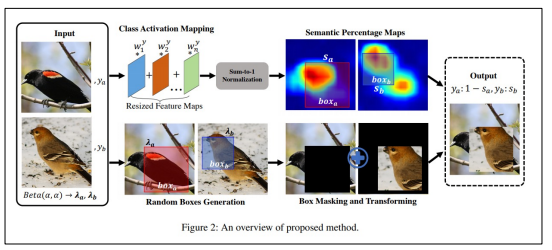
5) SnapMix
- CAM(Class Activation Map)을 이용해 이미지 및 라벨을 mixing하는 방법
- 영역 크기만을 고려해 라벨을 생성했던 CutMix와 달리 영역의 의미적 중요도를 고려해 라벨을 생성
6) CropNonEmptyMaskIfExists
- object가 존재하는 부분을 중심으로 crop 할 수 있다면 model의 학습을 효율적으로 할 수 있음
A.augmentations.crops.transforms.CropNonEmptyMaskIfExists(height=256,width=256)
2.4 SOTAModel
1) HRNet
- 최근 segmentation에서 좋은 성능을 냄
2.5 Scheduler
constant learningrate는 발산 혹은 local minima에 빠질 수 있음
그래서 scheduler를 사용하여 빠른속도, 높은정확도를 갖는 lr을 사용해야한다
1) CosineAnnealingLR
- Learning rate의 최대값과 최소값을 정해, 그 범위의 학습율을 Cosine 함수를 이용해 스케줄링하는 방법
- 최대값과 최소값 사이에서 learning rate를 급격히 증가시켰다가, 감소시키기 때문에 saddle point, 정체 구간을 빠르게 벗어나게 함

2) ReduceLROnPlateau
- metric의 성능이 향상되지 않을 때 learning rate를 조절하는 방법
- Local minima에 빠졌을 때 learning rate를 조절하여 , 효과적으로 빠져나옴

3) GradualWarmup
학습을 시작할 때 매우 작은 learning rate로 출발해서 특정 값에 도달할 때까지 learning rate를 서서히 증가시키는 방법 • 이 방식을 사용하면 weight가 불안정한 초반에도 비교적 안정적으로 학습을 수행할 수 있음
• backbone 네트워크 사용시에 weight가 망가지는 것을 방지

2.6 HyperparameterTuning
1) GradientAccumulation
모델의 weight를 매 step 마다 업데이트하지 않고, 일정 step 동안 gradient를 누적한 다음 누적된 gradient를 사용해 weight를 업데이트하는 방법
• 배치 사이즈를 키우는 장점이 있음
2.7 Optimizer/Loss
Optimizer
1. Adam
2. AdamW
3. AdamP
4. Radam
5. Lookahead optimizer
- Adam이나 SGD를 통해 k번 업데이트 후, 처음 시작했던 point 방향으로 1 step back 후, 그 지점에서 다시 k번 업데이트를 시작하는 방법
- Adam이나 SGD로는 빠져나오기 힘든 Local minima를 빠져나올 수 있게 한다는 장점Loss
Loss
- segmentation에서 cross entropy뿐 아니라 여러 loss가 존재하고 hybrid loss로 여러개의 loss를 합쳐서 사용하기도한다

'부스트캠프 AI Tech 2기 > 2기 CV P-Stage-Semantic Segmentation' 카테고리의 다른 글
| Semantic Segmentation trash recycle 후기 (0) | 2021.11.07 |
|---|---|
| Semantic Segmentation 대회에서 사용하는 방법들 2 (0) | 2021.10.20 |
| High Performance를 자랑하는 Unet 계열의 모델들 (0) | 2021.10.20 |
| FCN의 한계를 극복한 model 2 성능적인 측면에서의 극복 (0) | 2021.10.20 |
| Semantic Segmentation의 기초와 이해 (0) | 2021.10.19 |