
1.baseline이후에 실험 해봐야할 사항들 II
1.1Ensemble
1) k-fold 앙상블
2) epoch 앙상블 ( 성능이 괜찮은 epoch의 체크포인트들을 로드하여 모델을 앙상블 )
3) SWA (stochastic Weight Averaging)
- 각 step 마다 weight를 업데이트 시키는 SGD와 달리 일정 주기마다 weight를 평균내는 방법

4) Seed 앙상블
- 모든 요소들은 같게하고 Seed만 바꿔서 학습을 여러번하여 ensemble
5) Resize 앙상블
- Input 이미지의 Size를 다르게 학습하여 ensemble
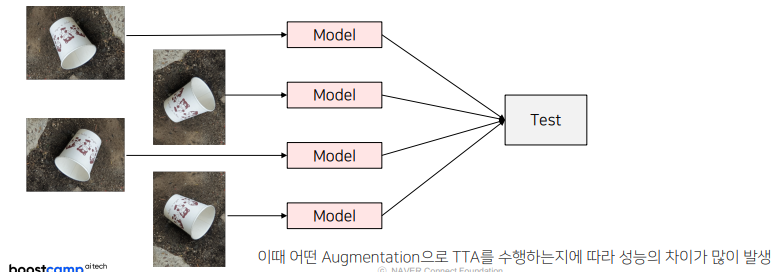
6) TTA (test time augmentation)
- Test set으로 모델의 테스트 할 때, augmentation을 수행한다음 수행한 결과를 평균낸다
- 같은 모델을 활용하는것
- 만약 rotate를 사용했으면 결과를 낼때 이미지를 다시 원래대로 돌려야한다
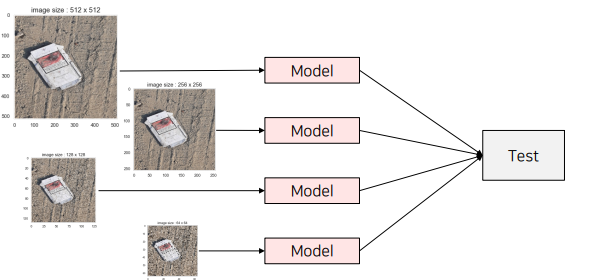
- 학습때와 다른 size의 Input 이미지를 이용해 TTA
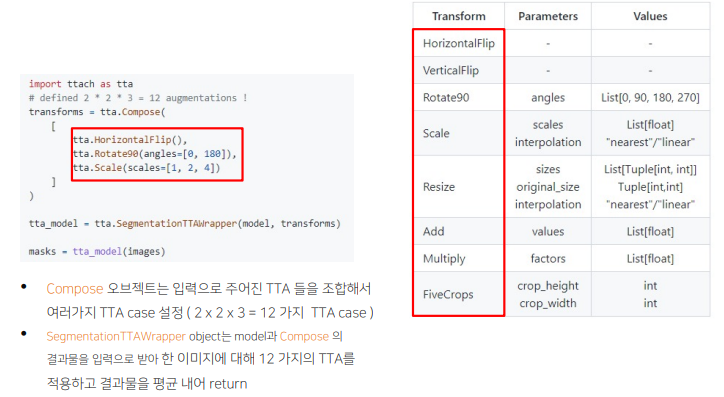
- TTA 코드 구현
아래의 라이브러리를 사용하면 inference하고나서 원래의 사이즈, 변환으로부터 return해줘야하는데 이를 모두 적용시켜줌
1.2 PseudoLabeling
- Labeling이 없는 데이터에 대해서 추가로 labeling을 한 이후에 train에 참여시킴 -> training데이터양이 증가하는 효과
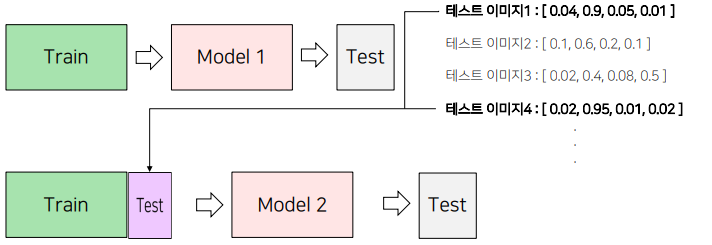
순서
1) 모델 학습을 진행
2) 성능이 가장 좋은 모델에 대해 Test 데이터셋에 대한 예측을 진행
• 이 때 Softmax를 취한 확률값이나 Softmax를 취하기 전의 값, torch.max를 취하기 전의 값을 예측
• Test 데이터셋은 Model 1의 예측값이 threshold (예 : 0.9) 보다 높은 결과물을 이용
3) 2단계에서 예측한 Test 데이터셋과 Train 데이터셋을 결합해 새롭게 학습을 진행
4) 3단계에서 학습한 모델로 Test 데이터셋을 예측
1.3 외부 데이터 활용
1.4 그 외
한정된 시간동안 GPU가 쉬지 않도록 미리 실험용 코드 작성
2. 대회에서 사용하는 기법들 소개
2.1 최근 딥러닝 이미지 대회의 Trend
solution 1
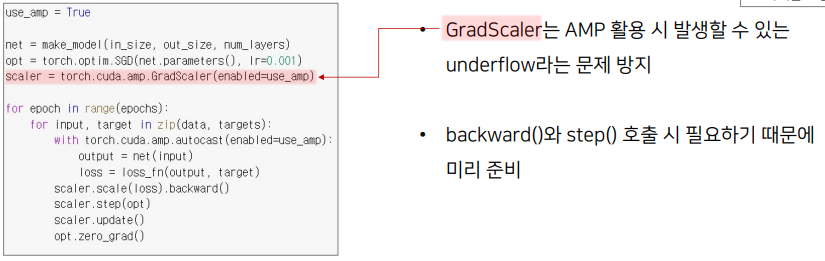
1) Mixed-PrecisionTrainingofDeepNeuralNetworks (FP16)
- 속도를 높이기 위해 FP16 연산과 정확도를 유지하기 위한 FP32 연산을 섞어서 학습
- AMP없이는 모든 계산이 defaultprecision인 torch.float32로 계산
2) 가벼운 상황으로 실험
- 일부 데이터사용
- 단일 fold로 검증
- 이미지를 resize하여 줄임 (이미지를 resize해서 저장해놓으면 augmentation단계에서 빠른 속도를 낼 수 있음)
하지만 LB와 validation score 간의 어느정도 상관관계가 있어야함
3) 가벼운 모델로 실험
- Efficientnet을 사용할경우 b7이 아닌 b0로 사용
solution 2
1) Resize
- 주어진 data를 모두 resize시켜 학습 → testset에 대해 예측된 Mask를 원본 size로 복원
2) SlidingWindow
Imagesize가 크기 때문에 window단위로 잘라서 input으로 넣는 기법
2-1) SlidingWindow(Overlapping)

- stride가 작아지면 겹치는 부분이 많아진다
-> input image수가 많아지면 겹치는 영역이 많아지고 다양한 정보가 추출된다.
2-2) SlidingWindow(Non-overlapping)
stride = window size

Sliding Window 정리
- Stride를 작게 설정하면 크게 설정했을 때보다 상대적으로 object를 구분하기위한 필요한 정보를 포함 시킬 수 있음
- Inference할 때, Stride를 작게 설정하면 중복되는 부분을 Ensemble해서 약간의 성능 향상을 얻을 수 있음
- 일반적으로 겹치게 자르면 다양한 정보를 얻을 수 있지만 학습데이터의 양이 많이 늘어나게 될 수 있으며,중복되는 정보가 많아 학습 데이터가 늘어나는 양에 비해서 성능의 차이는 적고 학습 속도가 오래 걸리는 문제 발생
3) 그 외의 Tip_1
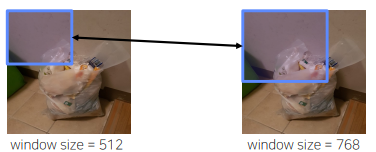
- 일반적으로 train에 사용된 slidingwindow의 크기 (e.g.512)와 Inference에 사용되는 slidingwindow의 크기가 동일해야 한다고 생각하는 경우가 많음
- 하지만,inputimage와 inference(test)image의 크기가 꼭 같을 필요 없음
- Example:Inferenceimage의 slidingwindow의 크기 (e.g.768)가 커지면 더 많은 주변 정보를 통해서 prediction할 수 있으므로 성능의 정확도가 올라가는 경우가 경험적으로 많았음
4) 그 외의 Tip_2
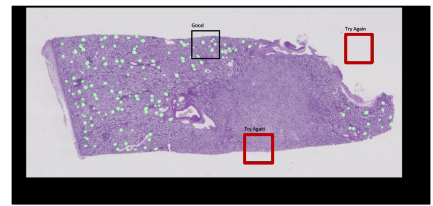
- SlidingWindow를 적용하면 아래와 같이 유의미하지 않은 영역들이 잡히는 경우가 많음
- 해결 방안 :“background”만 수집된 부분은 조금만 샘플링
- 효과: Solution의 경우 학습속도상승
5) 그 외의 Tip_3
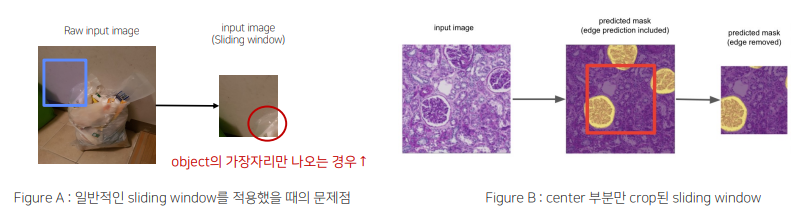
- SlidingWindow를 적용하면 [FigureA] 처럼 유의미하지 않은 영역들이 잡히는 경우가 많음
- 해결 방안 :Prediction후에 object가 제대로 나온 center 부분만 Crop[FigureB]
6) 그 외의 Tip_4
- 전체 이미지에서의 유의미하지 않은 영역들이 잡히는 경우가 많음
- 해결 방안 :segmentation/objectdetection을 통해서 object부분을 먼저 찾은 후 Crop
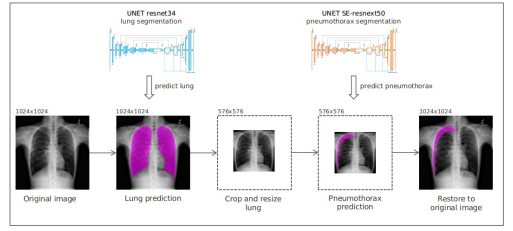
6) 그 외의 Tip_7
- Task가 Binary Classification인 경우 threshold를 0.5로 끊는게 굳이 정답이 아닐 수 있다
- Threshold(hyper-parameter)를 잘 search 하면서 실험을 진행
2.2 model의 개선하기 위한 Tips
1) Output Image 확인
- 큰 Object를 잘예측하는지
- 작은 Object를 잘예측하는지
- 특정 class에 대해 잘 맞추는지
2.3 LabelNoise가 있는 경우 Tips
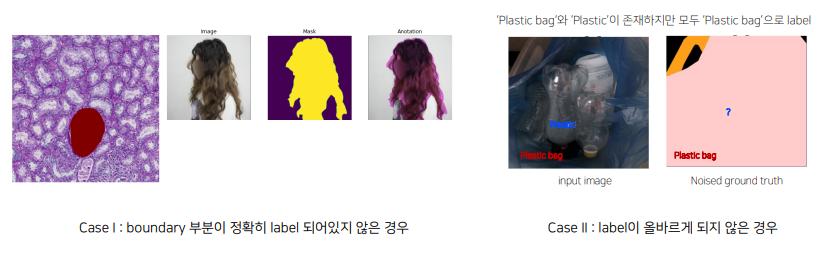
[LabelNoise가 발생하는 원인]
- 일반적으로 segmentation에서의 annotationtask는 픽셀 단위로 이루어지기 때문에 어려움이 존재
- annotationGuide가 주어지더라도 사람마다 기준이 다를 수 있음
- 사람이기 때문에 annotation실수도 존재
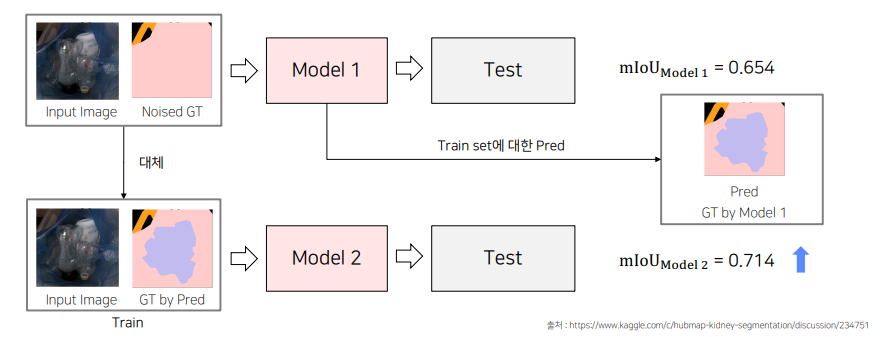
1) Solution_1 Label Smoothing

2) Solution_2 Pseudo-labeling
너무 noise한 값들은 가진 image는 제거를 해준다
2.4 최근 딥러닝 이미지 대회의 평가 Trend
기존 평가 방식인 Accuracy,mIoU 이외에 다양한 평가 방식을 추가
- 학습 시간의 제한이 있는 경우
- 추론 시간의 제한이 있는 경우
- 속도 평가를 하는 경우
만약 한가지 모델만 사용해야한다면 epoch ensemble 또는 swa 또는 tta를 사용해보는 것도 좋다
'부스트캠프 AI Tech 2기 > 2기 CV P-Stage-Semantic Segmentation' 카테고리의 다른 글
| Semantic Segmentation trash recycle 후기 (0) | 2021.11.07 |
|---|---|
| Semantic Segmentation 대회에서 사용하는 방법들 1 (0) | 2021.10.20 |
| High Performance를 자랑하는 Unet 계열의 모델들 (0) | 2021.10.20 |
| FCN의 한계를 극복한 model 2 성능적인 측면에서의 극복 (0) | 2021.10.20 |
| Semantic Segmentation의 기초와 이해 (0) | 2021.10.19 |